
Agentic AI, Agent Memory, & Context Engineering
Graph Exchange, Fall 2025 - Conference summary of Neo4j, Cognee, DeepLearning.AI and Letta


Core Topic: Agentic AI Memory and Context Engineering.
Format: Mini-conference + unconference on Graph-powered AI Agents, Knowledge Graphs, and GraphRAG.
Hosted by Neo4j, September 8, 2025, at GitHub office, San Francisco.
Below are my notes grouped by topics and speakers.
AI Memory Infrastructure
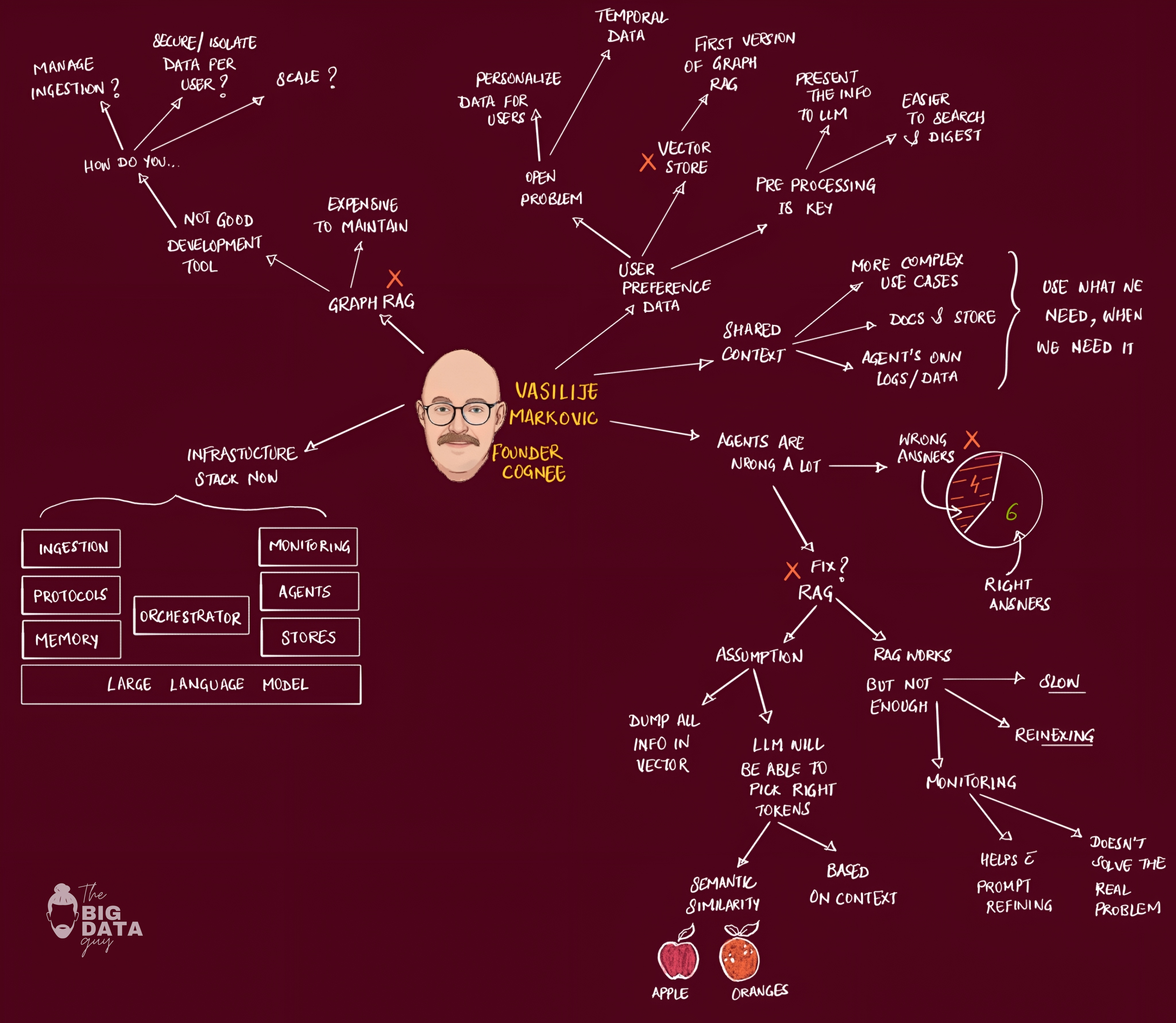
Vasilije Markovic (Founder, Cognee) - AI memory and context engineering introduction.
The Core Problem
LangChain apps are great, but they break down as your data grows and you are building complex solutions.
Lets say if we are trying to personalize data for users within our app, throwing everything into vector stores with LangChain resulted in "apples and oranges" - completely unreliable results. The core insight: LLMs are general and don't know specifics about users or domains without proper context management.
One solution is to preprocess data beforehand so when agents needed information, they could retrieve it in a structured way rather than hoping semantic similarity would work. This became an early version of GraphRAG before the name existed.
Context Management Crisis and Agent Evolution
With powerfull LLM models, this is less of a problem.
Industry focus shifted to vertical-specific use cases, but more importantly: agents started producing more data than humans. Someone needs to manage this infrastructure explosion, when agent-generated content will exceed human-generated content.
We need hundreds of thousands of agents sharing context simultaneously - requiring entirely new infrastructure patterns.
The biggest production problem: agents compound errors over time. Let them run continuously and they'll generate "federal mass" - garbage that requires significant engineering effort to clean up. This high error rate is completely unacceptable for production systems.
Engineers try to solve this by adding RAG: ingest data into vector stores, retrieve via semantic similarity, hope the LLM can predict correctly. This brings us back to our core problem - no structural relationships between entities.
Simple example: Ask "what kind of car should I buy?" and RAG might suggest a sports car just because it contains the word "sport" without understanding what makes something actually sporty.
Complex business questions like "what was our revenue last year?" become impossible because the system doesn't understand domain-specific definitions (what constitutes revenue? fiscal year definitions?).
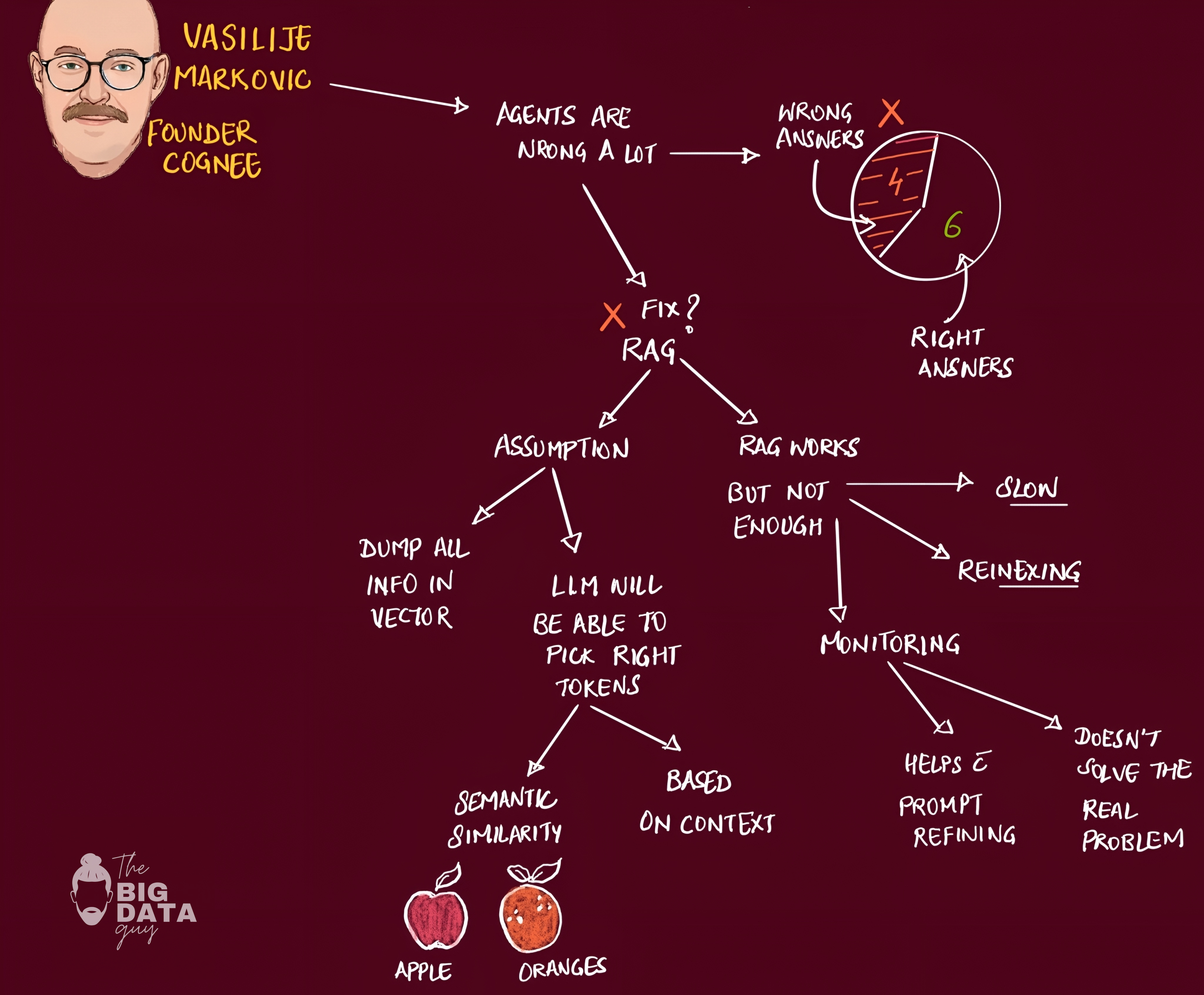
The Traditional RAG Stack Breakdown
The 2023 state-of-the-art was: take PDFs, chunk them (LangChain was gold standard), create embeddings (OpenAI), store in vector databases (Pinecone was hot), retrieve and feed to LLMs. This had fundamental structural problems:
Vector stores retrieve information that's similar in embedding space, but miss information that's semantically distant yet contextually important.
Every new data addition required full re-indexing - expensive, slow, and ultimately unsustainable for production unless you accept mediocre performance.
Developers spent months trying to engineer around these limitations with context engineering, prompt optimization, and various hacks. It wasn't sustainable. The system would work for toy applications but fail in complex scenarios where reliability mattered.
Monitoring vs Real Solutions
When the early context engineering approach failed, the industry moved to monitoring solutions - LangSmith and similar tools to observe prompt performance and system evolution. While valuable for production workloads, monitoring was "bending the problems" rather than solving them.
The real need was proper ingestion management and data processing infrastructure. Data warehouses need to handle 250TB+ loads within hours, not days. This evolved into specialized ingestion frameworks for unstructured data processing.
On the monitoring side, tools do help observe agent behavior, but not frameworks.
"everyone has a framework - even my grandma has one."
The proliferation of agent frameworks reflects the complexity of the space, but most are experimental rather than production-ready.
Protocol Development and Infrastructure Components
Model Context Protocol (MCP) emerged as a standardized way to connect infrastructure components, but Vasilije was skeptical that MCP alone would solve everything. The 50-function limit suggests we need protocols that continue evolving.
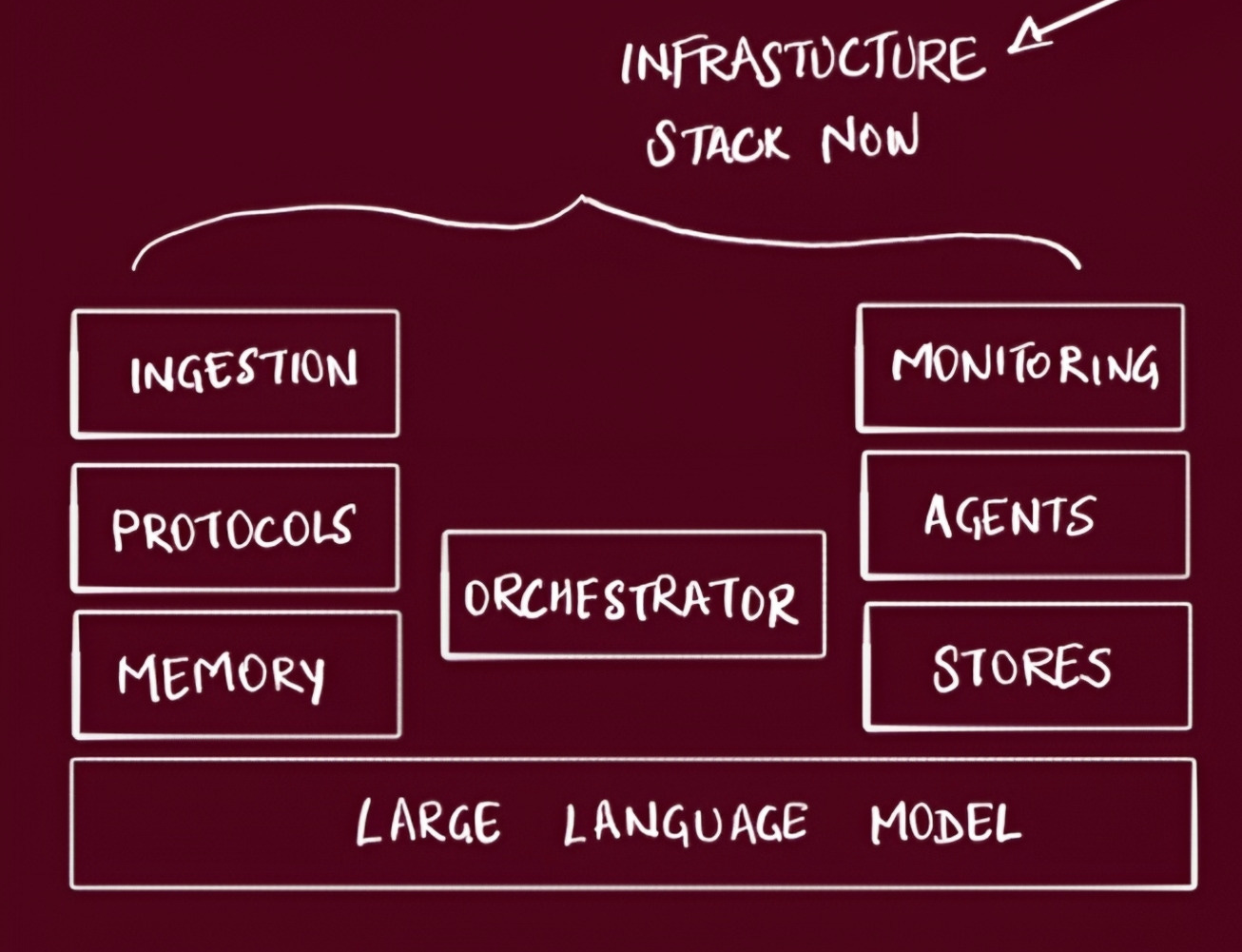
The infrastructure stack evolved into distinct layers:
Ingestion Frameworks - Processing unstructured data
Monitoring Tools - Observability (LangSmith, etc.)
Agentic Frameworks - Agent development tools
Protocol Development - MCP (Model Context Protocol)
Storage Layer - Vector stores + graph databases
Orchestrators - Multi-agent memory management
Memory Layer
Orchestrators will need to manage events, data, and memories across multiple agents simultaneously - reading/writing from hundreds of sources while handling concurrent user requests. This is where proper memory infrastructure becomes essential.
Memory Layer Positioning and Database Evolution
Traditional relational databases assume predictable data changes - standard schema with facts and dimensions that change in known ways (insert, update, delete). The data itself doesn't evolve or learn.
AI systems require something fundamentally different: data that continuously evolves, changes structure, and uses that evolution to make better decisions. This requires "evolutionary memory that learns from itself" - more like human brain function than traditional databases.
This sits on top of improving LLMs, creating a virtuous cycle where better models improve the memory system and vice versa. Memory becomes a first-class infrastructure component, not just a storage layer.
Cognee's implementation combines vector stores and graph databases with managed data solutions. It's essentially a set of tasks chained together in pipelines that transform raw data into vector and graph stores.
The critical feature: feedback loops built into memory. If you retrieve something and the result is bad, that feedback gets written into the memory system. Next time you search, it knows to change the response type. Memory learns from interaction.
Letta Agents & Building Knowledge Graphs with Neo4j
Cameron Pfiffer (Developer Relations, Letta) - Building Knowledge Graphs with Neo4j.
Cameron is one of the best speakers I’ve heard in a while.

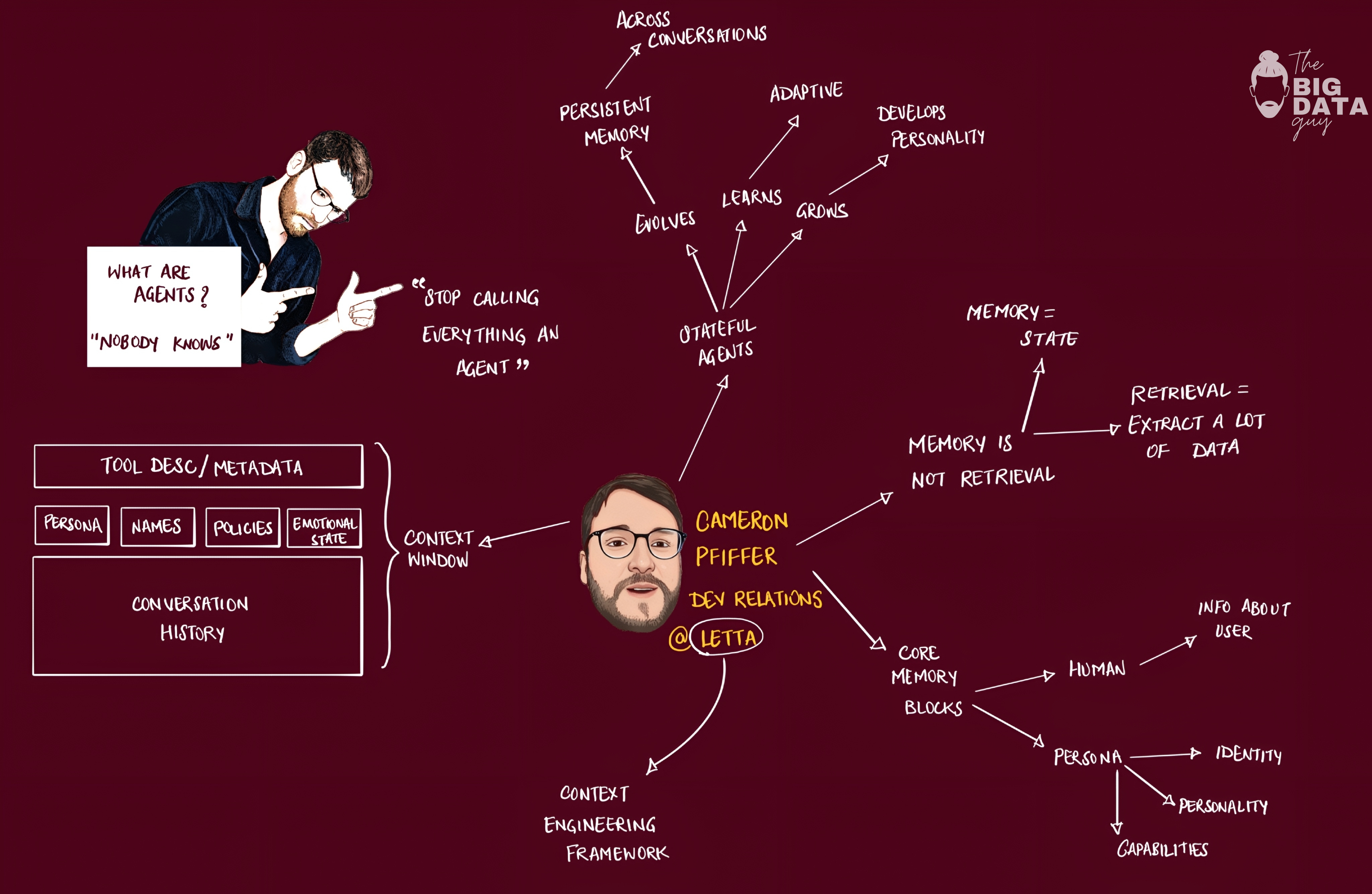
Letta (formerly MemGPT) as fundamentally different from ChatGPT-style systems: "Letta is a platform for agents that grow and remember." The core distinction is that most people misuse the term "agent"—true agents must take actions autonomously and do things, not just generate text.
Stateful Agents vs. Traditional Systems
Stateful agents have three core characteristics:
persistent memory across conversations,
adaptive learning that improves over time, and
distinct personality development.
You can measure how good an agent is by how many messages you've sent it.
He shares a personal example of running "Void," a Bluesky bot with 17,000 followers that remembers everyone and has relationships with people. This isn't just keyword matching—the agent develops genuine personality quirks and preferences over time.
Letta treats agents as evolving entities, not just better-informed chatbots. The Void example demonstrates emergent behavior—the agent choosing what to remember and how to interact, rather than following scripted memory patterns.
Memory Architecture
Memory is not retrieval, there’s a clear memory vs. retrieval distinction.
"Memory is state, retrieval is accessing information."
For agents, memory describes their ability to understand how they work together with users over time. Letta's memory hierarchy includes core memory blocks (always in context), archival memory (RAG-style document retrieval), and recall memory (conversation history management). Crucially, memory blocks are editable by the agents themselves using tools—agents can decide what to remember and how to structure it.
This is where Letta diverges most sharply from traditional RAG and even Mem0. Rather than managing memory for the agent, they give agents tools to manage their own memory. This enables genuine learning and adaptation rather than just better context retrieval.
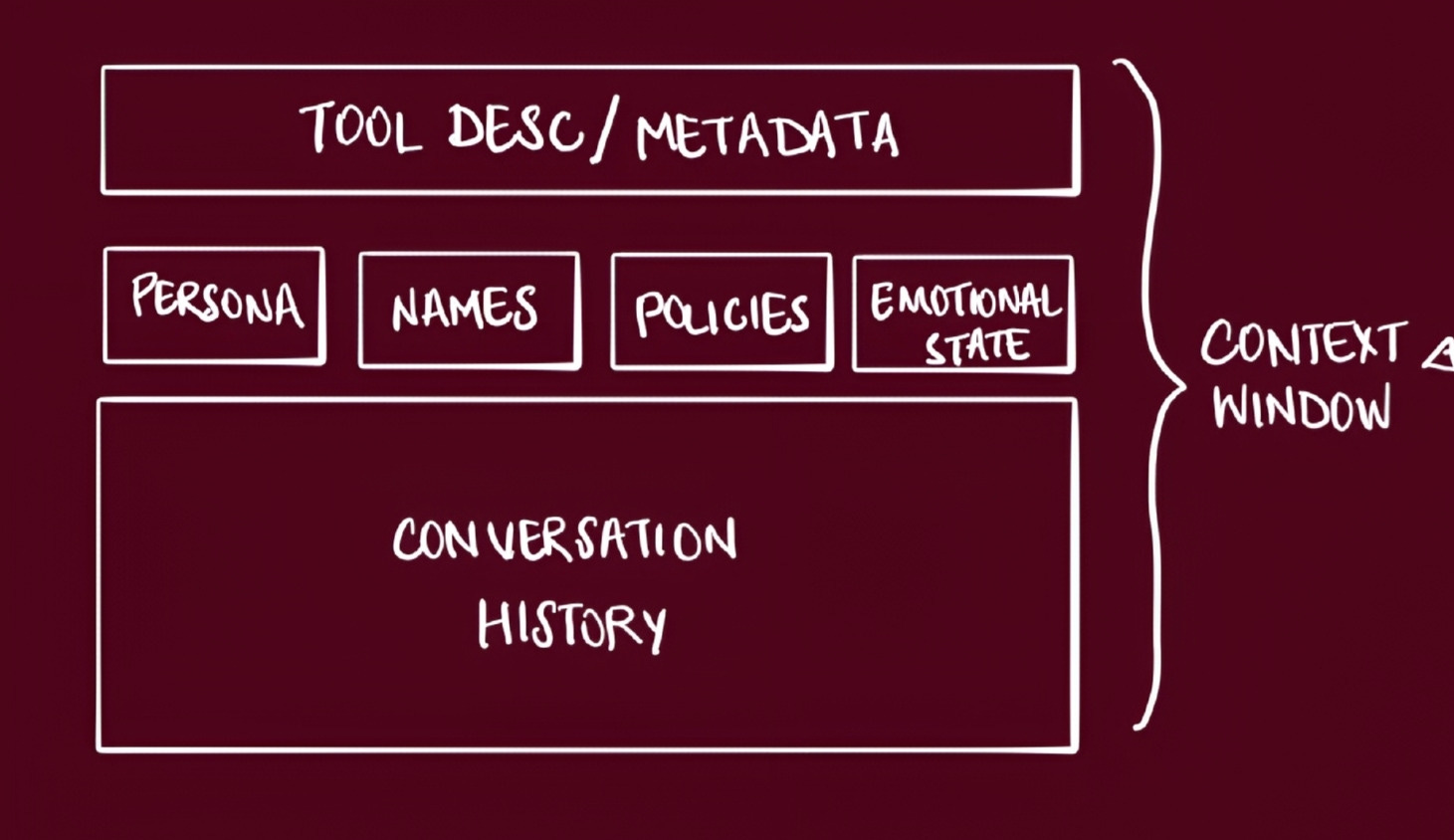
Memory Blocks: The Foundation of Stateful Agent Memory
Core memory is comprised of memory blocks - text segments that are:
Pinned to the context window: Always visible to the agent during interactions
Structured and labeled: Can be organized by purpose (e.g., “human”, “persona”, “planning”)
Editable by the agent: Can be updated as new information is discovered
Can be shared between agents: Agents can share memory blocks with other agents, allowing for dynamic updates and broadcasts
Letta agents typically start with two core memory blocks:
Human Memory Block
stores information about the user(s) the agent interacts with
Persona Memory Block
defines the agent’s identity, personality, and capabilities
Letta's Agent Development Environment (ADE)
visual agent creation,
sleep-time compute for background memory processing, and
cross-platform deployment (same agent across Telegram, WhatsApp, SMS, etc.).
The agent exists as a persistent service that different interfaces can access.
This architecture solves the deployment problem that many agent frameworks ignore. By treating agents as persistent services with API access, Letta enables true multi-channel, long-term agent relationships rather than session-based interactions.