
Journey Through Distributed Systems: Mental Models for the Real World

Picture this: You deploy a "simple" feature on Friday afternoon. Everything works perfectly in testing. Monday morning, you're getting paged because users can't log in, payments are failing, and somehow your recommendation engine is returning cat videos to dog lovers. Welcome to distributed systems, where Murphy's Law has a PhD and your assumptions go to die.
I’ve spent over 12 years as a software engineer and solutions architect, and during that time I’ve been humbled by distributed systems. In this post I want to share the key mental models that have guided me – lessons learned from real-world experience and inspired by some of the top books in the field.
Large scale distrubuted systems can be intimidating, but with the right models in mind, they become much more approachable. My goal is to explain these concepts in simple language, through the lens of an industry practitioner.
When new engineers build applications, they assume things would work mostly like a single-machine program – this is good for POCs and test applications, but doesn’t work in real-world. I still remember the first time a minor network glitch took down an entire service I worked on. A single slow database call cascaded into timeouts everywhere. It drove home a hard truth: in a distributed system, the failure of a component you didn’t even know existed can render your entire application unusable.
Leslie Lamport’s famous quip captures it perfectly – you have to expect failures outside your control. Over the years, I also came to appreciate the flip side: distributed systems are born out of necessity.
Distributed systems arise out of necessity – when one machine can’t handle the load or storage, we have to distribute the problem
The breakthrough moment came when I stopped fighting distributed systems and started understanding their fundamental nature. Every confusing design decision, every seemingly over-engineered solution, every "why didn't they just..." question suddenly made sense once I grasped this core truth:
distributed systems are governed by exactly two forces—distance and failure.
That's it. Information can only travel so fast (thanks, physics), and when you have multiple components, more things can break. Once you internalize this simple reality, the entire landscape of distributed systems design becomes predictable and logical.
More computers, more problems – distance introduces latency, and multiple components mean independent failure modes
Think of it like learning to drive in a new city. At first, every intersection seems random and chaotic. But once you understand the underlying traffic patterns—rush hour flows, one-way streets, construction zones—you start anticipating what's coming next. The same mental shift happens with distributed systems.
In the next sections, I'll walk you through the five mental models that transformed how I approach these challenges:
dealing with network fallacies,
making CAP theorem trade-offs,
understanding consensus and replication,
managing time and ordering, and
designing for inevitable failures.
Each model builds on real scenarios I've encountered, complete with the mistakes I made and the lessons learned the hard way.
These five mental models directly address the three fundamental challenges every distributed system must solve:
scalability (how do we grow without breaking?),
performance (how do we stay fast despite distance and coordination overhead?), and
availability (how do we stay up when individual components fail?).
Each of the sections below would tackles different aspects of these challenges. The beauty is that these aren't separate problems to solve sequentially; they're interconnected challenges that inform each other. Get the mental models right, and you'll naturally make design decisions that balance all three concerns instead of optimizing for one at the expense of the others.
Dealing with Distance and Failure
One of the first mental adjustments you have to make is letting go of the convenient assumptions of a single-machine environment. In a monolithic system, we assume function calls are reliable and near-instant. In a distributed system, those assumptions break down dramatically. Sun Microsystems engineers famously catalogued this in the Eight Fallacies of Distributed Computing – common false assumptions that catch developers off guard:
The network is reliable.
Latency is zero.
Bandwidth is infinite.
The network is secure.
Topology doesn’t change.
There is one administrator.
Transport cost is zero.
The network is homogeneous.
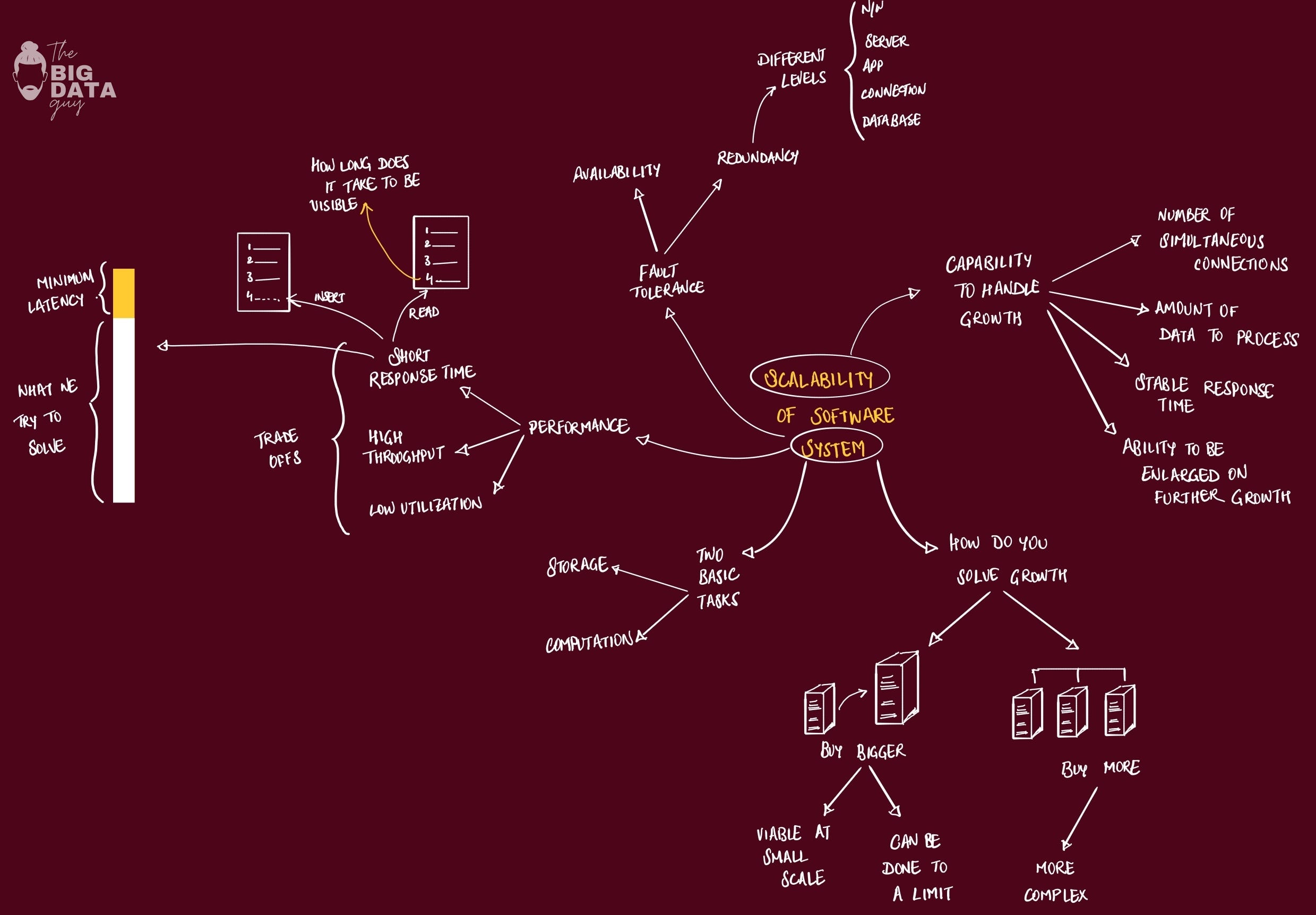
Scaling Out vs. Scaling Up: The Cost of Distribution
Scalability drives distribution: We distribute systems primarily to handle growth in load, data, or users that a single machine can’t.
Distribution has a COST: Adding nodes increases overhead from communication and coordination – you rarely get a linear speedup.
How do you quantify that cost?
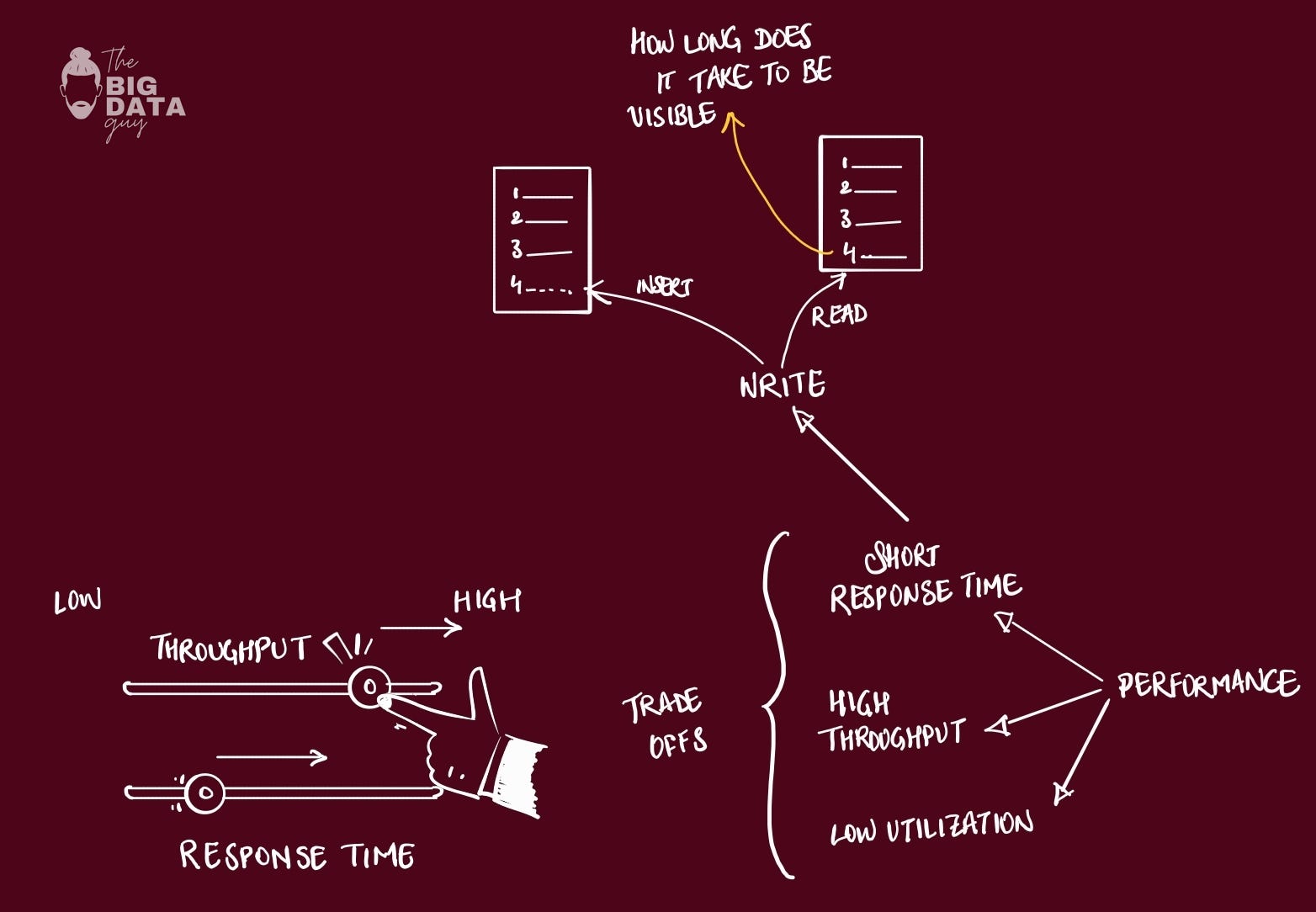
Performance isn't about going fast—it's about staying fast as you grow bigger. Broadly, performance is a combination of 3 things:
Response time (how fast one request completes)
throughput (how many requests you handle per second), &
resource utilization (how much of your hardware you're actually using)
You can't optimize all performance metrics simultaneously. Example, if you batch requests to increase throughput—processing 1000 recommendations at once instead of one-by-one → this gives you amazing resource utilization and total throughput numbers that would make management happy.
But individual users? They would waited ~30 seconds for their personalized feed instead of getting it instantly. High throughput often means higher individual latency, because you're essentially making people wait in line for more efficient batch processing.
The key point: performance optimization is really about choosing which user you're optimizing for: the individual who wants their request RIGHT NOW, or the system administrator who needs to serve a million users efficiently.
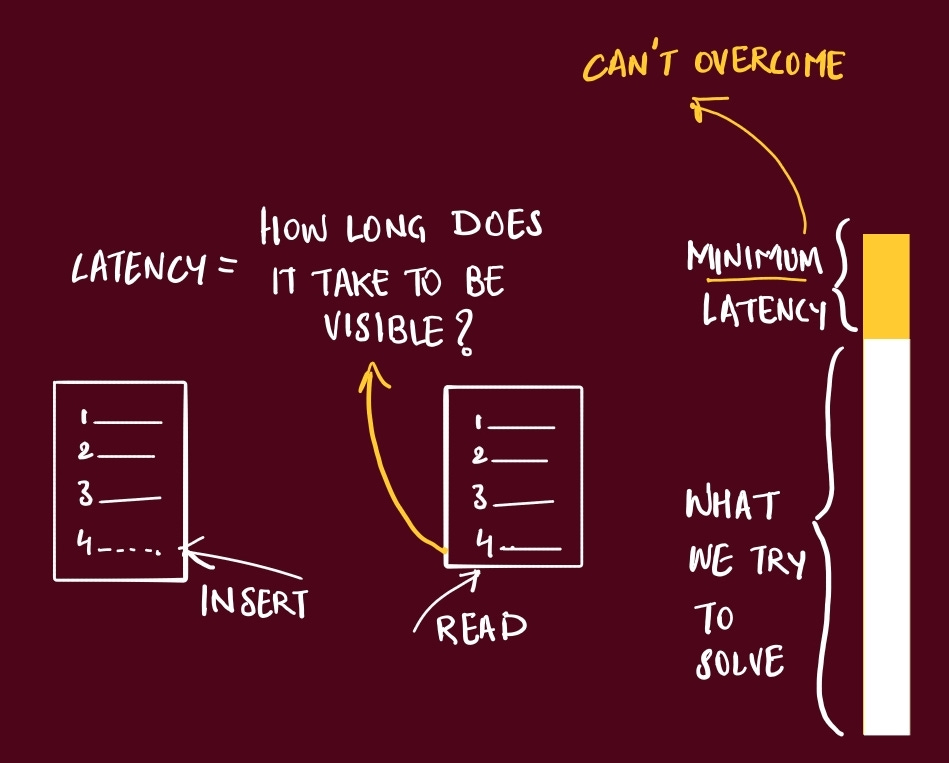
When I first calculated that it takes 40ms minimum for data to travel from New York to Tokyo and back, I realized that every distributed system is ultimately fighting physics. That user in Singapore clicking "load more results"? They're waiting for photons to bounce around fiber optic cables at 200,000 km/second.
There's a minimum latency you simply cannot defeat, no matter how much money you throw at the problem.
I learned to respect this "latency floor" quite early on. In 2013 I migrated a client environment to AWS, and when debugging slowness. We optimized databases, restructured app servers, threw more hardware at it—nothing worked. Turned out we were making API calls to a service 3,000 miles away.
Availability Math
Every additional component in your system multiplies your failure probability, not adds to it. If you have one server with 99% uptime, you get 99% system availability. Add a second server that also fails independently 1% of the time, You get 99.99% availability if they're redundant, or 98.01% if they're both required.
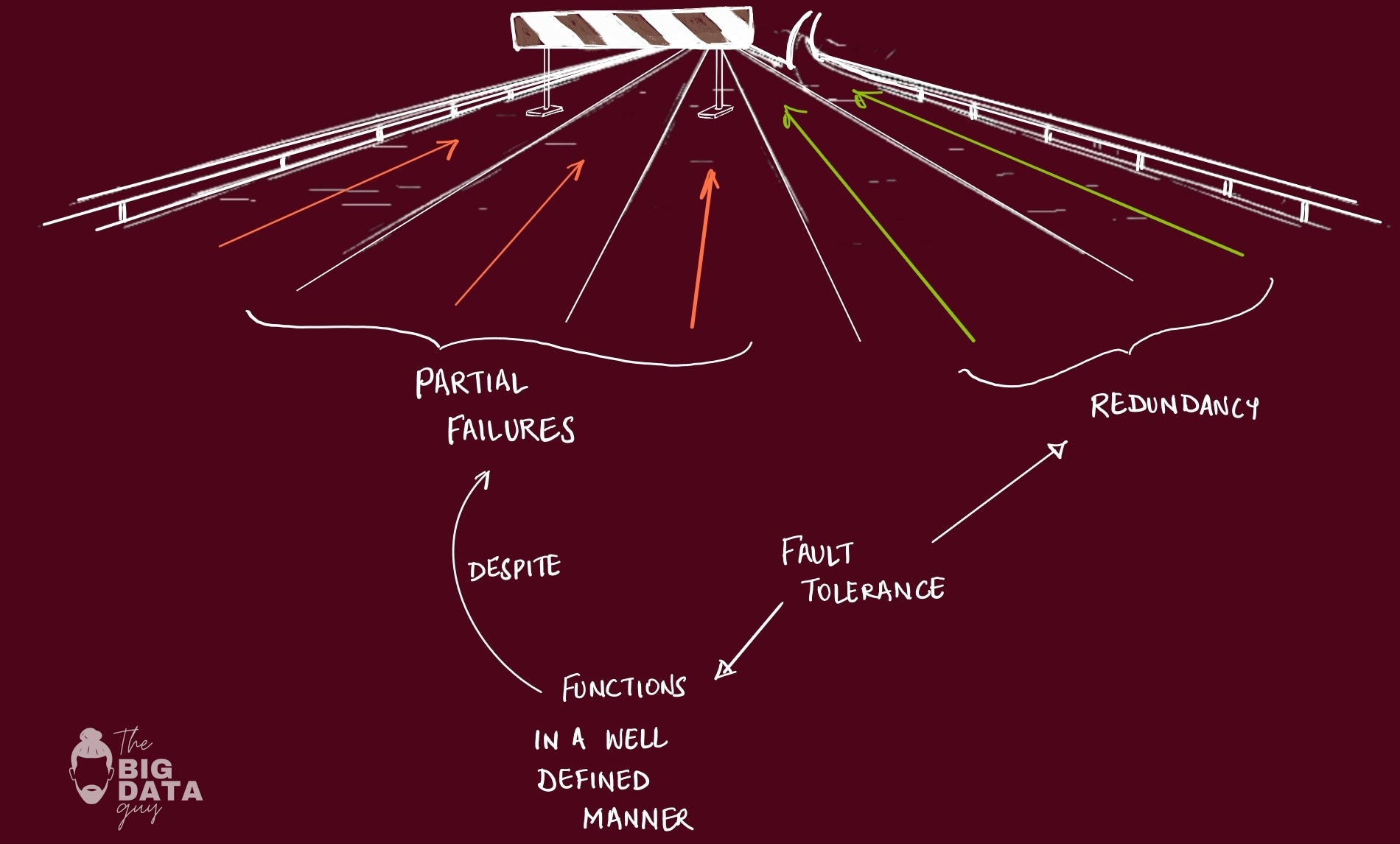
I once worked on a system that had 99.9% availability on paper—each of the 10 components was rock solid. But they were chained together serially, so our actual availability was 0.999^10 = 99.0%. We were getting an extra day of downtime per year just from architecture, not component failures.
The lesson: design for failure multiplication, not addition.
These challenges aren't random—they stem from exactly two physical constraints that govern every distributed system:
the number of nodes you need &
the distance between them.
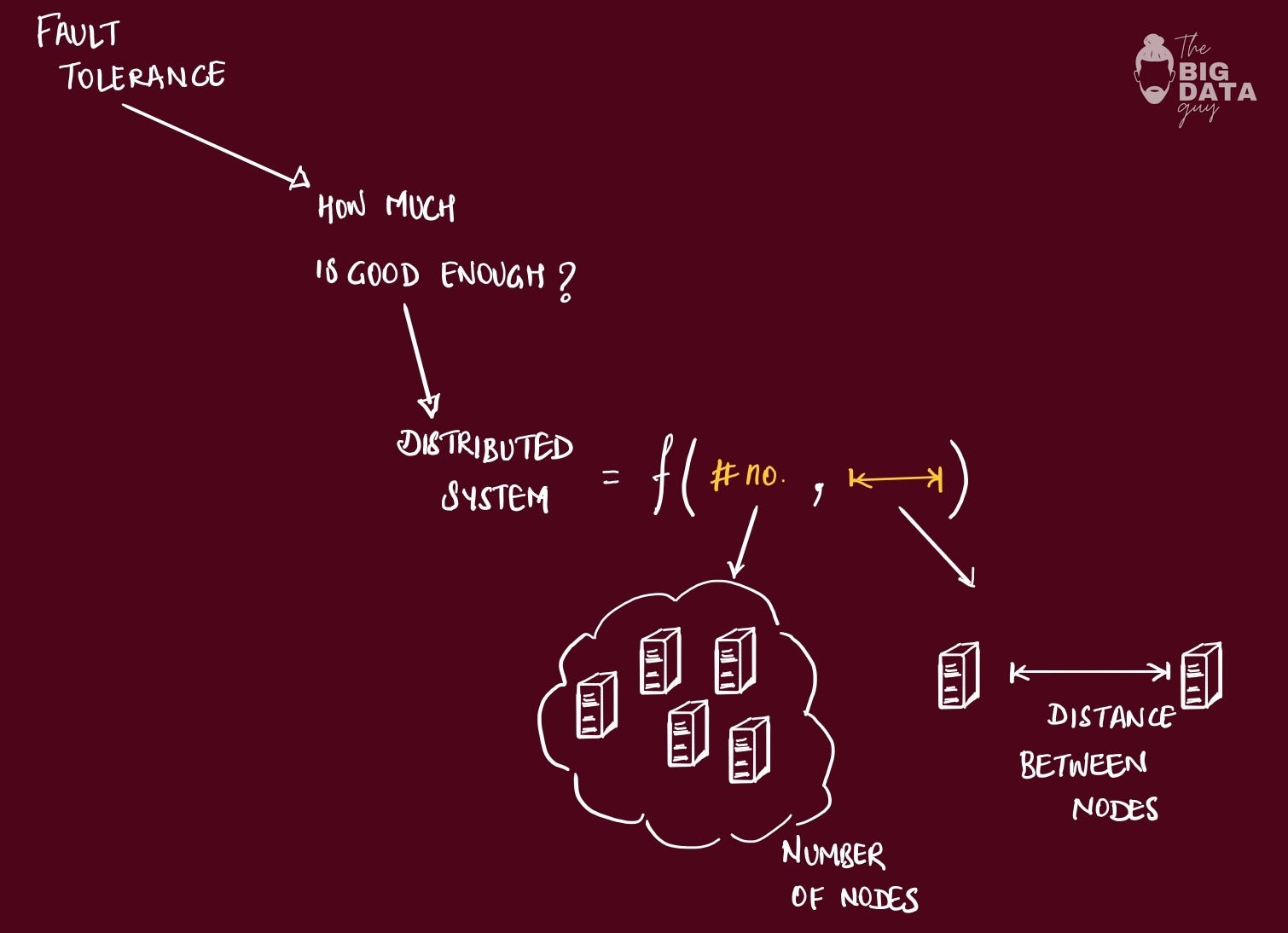
As a user of your app, all these details are abstracted away. The goal is to setup the system so it behaves as a single unit.
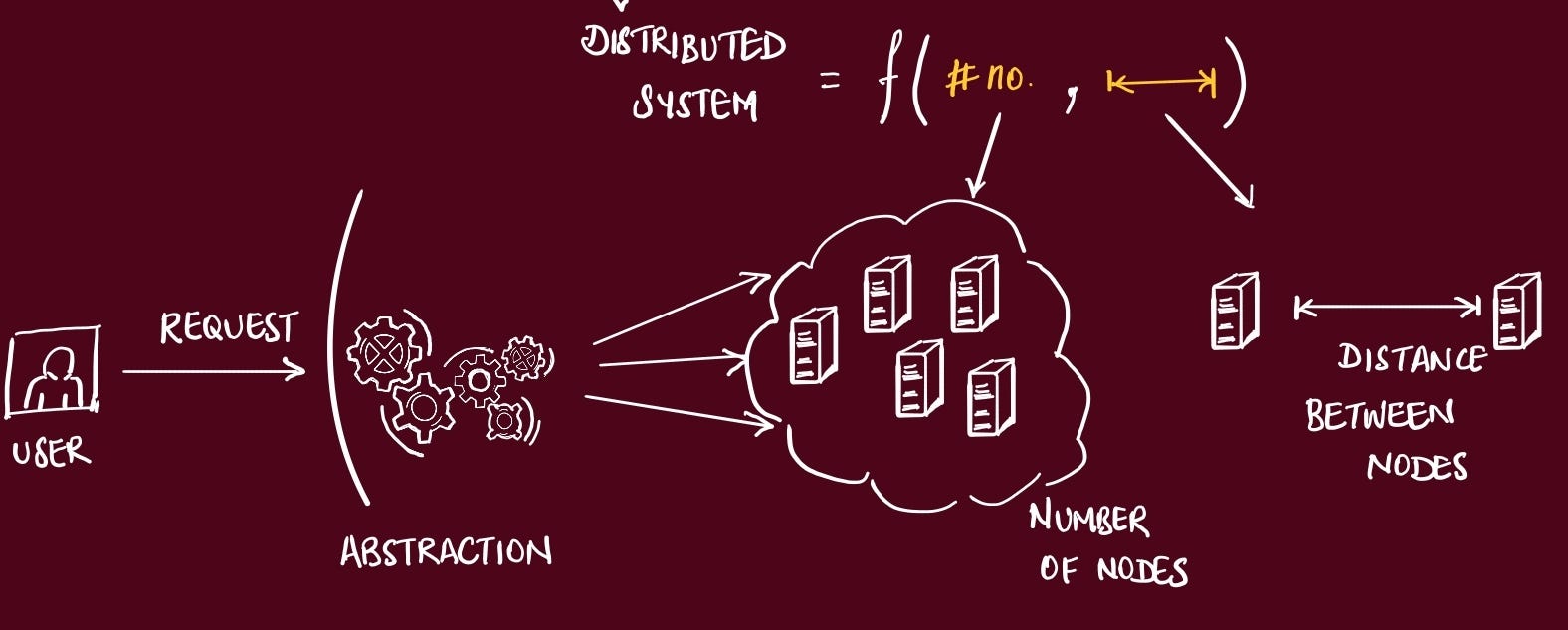
So, when trying to make the system more available, we have introduced redundancy, and added more nodes (servers). This brings up another challenge.
How do we distribute data between multiple nodes?
Every distributed systems problem ultimately comes down to two strategies: divide the work (partition) or copy the work (replicate).
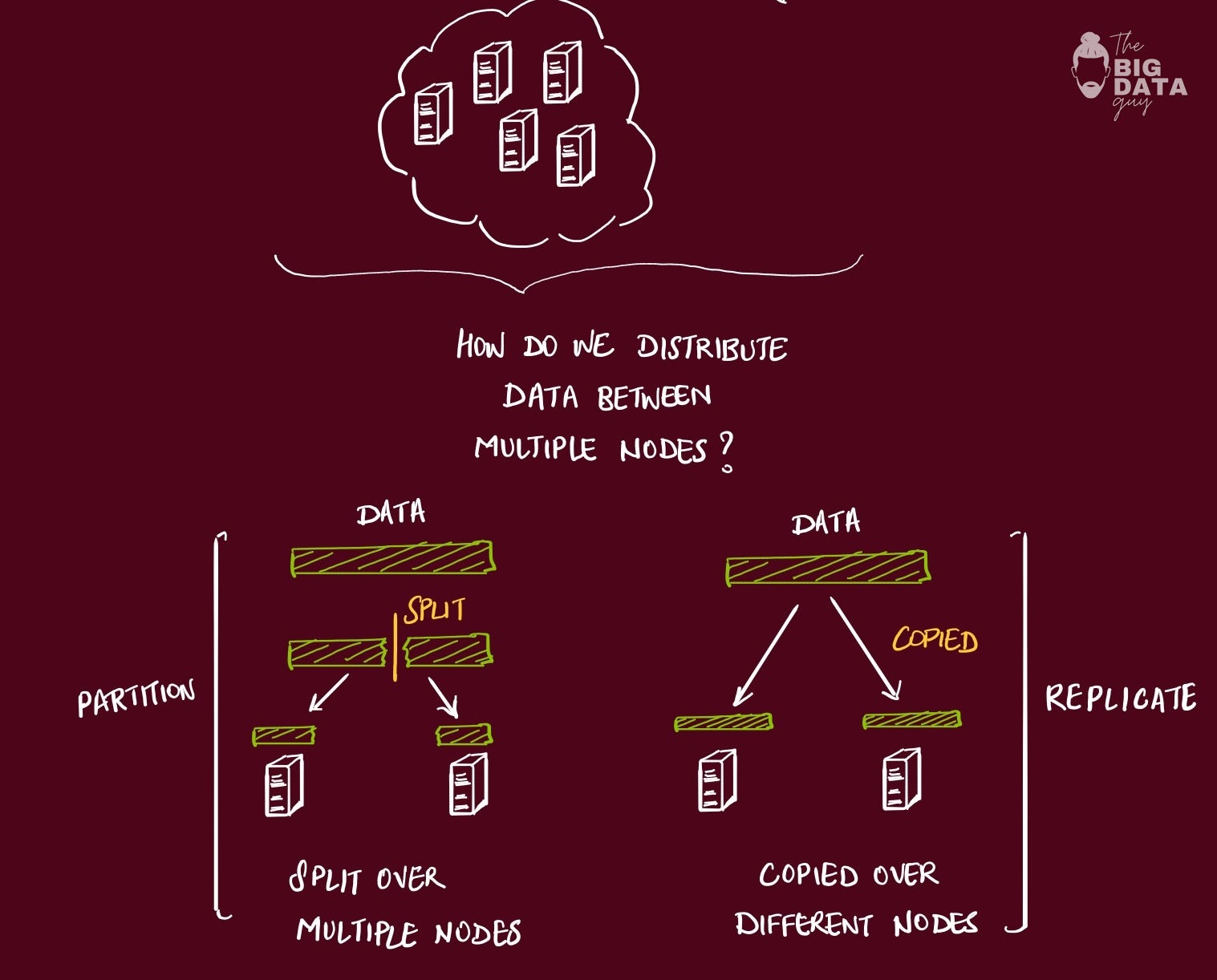
Partitioning is about dividing your data or computation across multiple machines so each one handles a subset. One of my old project had a scenario, when user database hit 10 million rows, we sharded it by user ID:
users 1-5M went to server A,
5-10M to server B.
Suddenly each server only dealt with half the data, making individual queries faster.
This is an important concept to know, because in modern applications, this have also been abstracted away behind some check-boxes and configs.
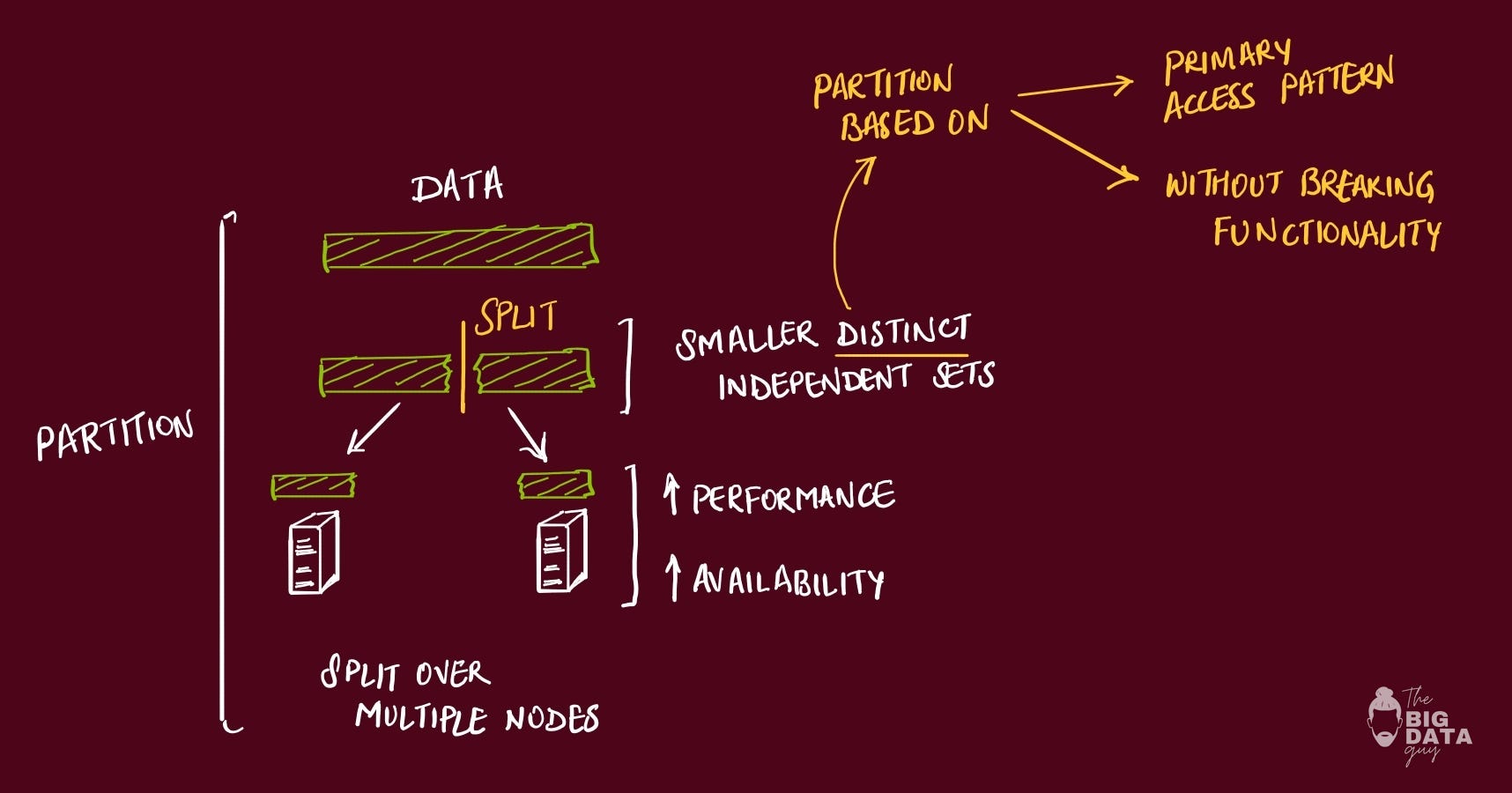
Replication is about copying data to multiple places for speed and reliability. Instead of one database struggling under read load, we created three read replicas. This enables us to untilize all server’s compute power.
Now reads could be distributed, but writes had to go to all copies, and keeping replicas in sync became a challenge.
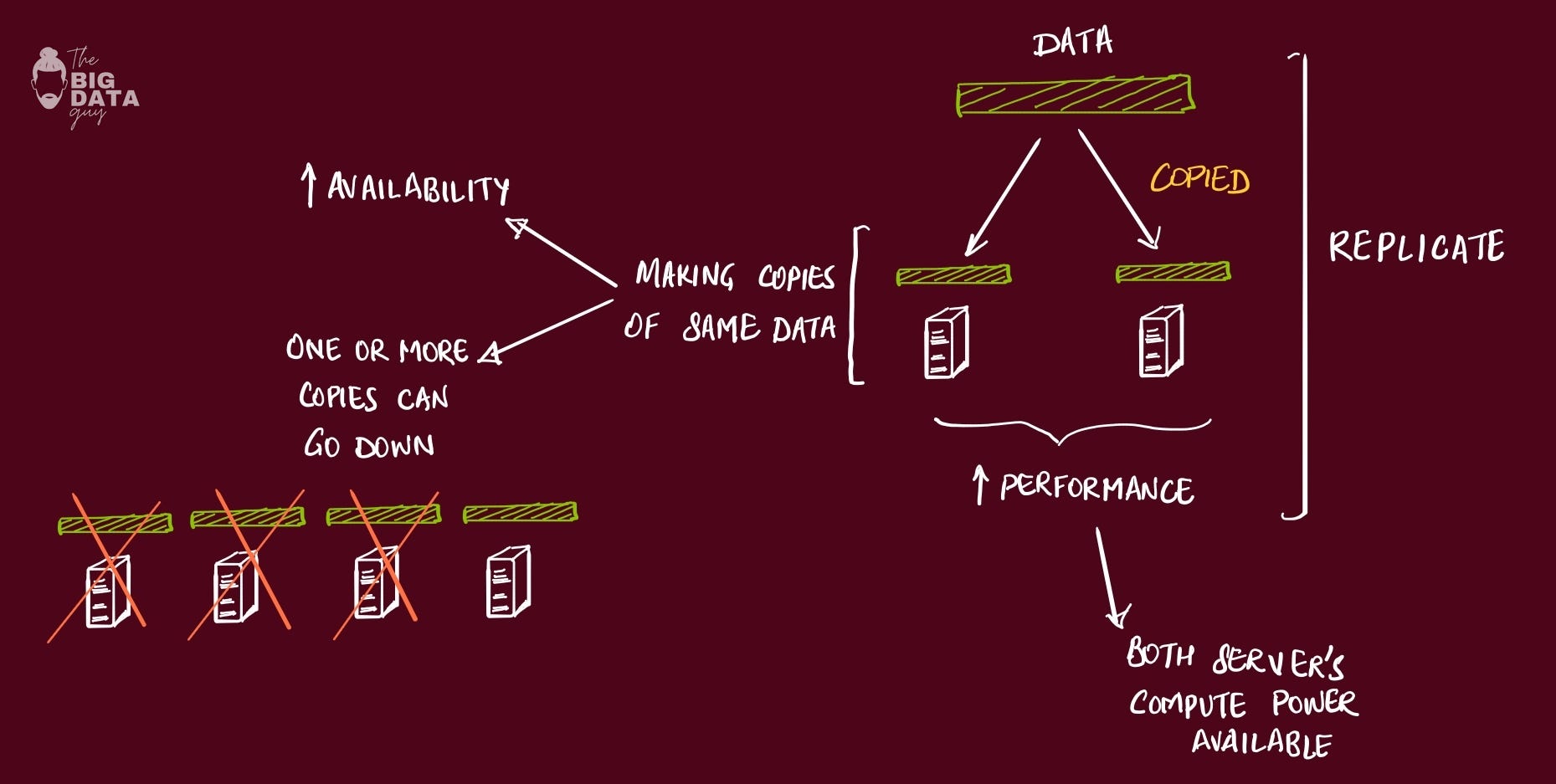
The mental model is knowing that partitioning helps with write scaling and storage limits, while replication helps with read scaling and fault tolerance.
Most real systems use both: partition to handle data size, replicate each partition for availability and read performance. The art is in choosing the right partitioning strategy (by user ID? by geography? by feature?) and the right replication consistency model for your use case.
So why do we put ourselves through this pain of dealing with these?
The answer is usually scalability. At some point, your data or traffic volume simply outgrows what a single machine can handle economically.
I’ve faced this in the form of a single database (SQL Server) that hit a wall on writes per second – no amount of tuning or vertical scaling could save it. We had to shard the data across multiple databases, entering the realm of distributed systems to keep growing.
Data & Traffic grows -> Scalability -> Distributed systems -> overheadsSplitting up the application into multiple parts isn’t without issues. you have to worry about:
overheads
increased development cost
coordination
writing robust distributed systems costs more – in time, complexity, and careful design – than writing a simple single-machine program.
Another hard lesson is that coordination is very hard. A mentor once told me: “If you can fit your problem in memory, it’s trivial – only distribute if you must.” This resonated later when I worked on an in-memory analytics job: we initially thought to split it across many servers, but it turned out one beefy server with enough RAM did the job simpler and faster. We deferred going distributed by optimizing single-node performance first.
Consistency vs. Availability: The CAP Trade-offs
One mental model that every engineer encounters is the CAP theorem. It’s a famous concept introduced by Eric Brewer, later proved by Gilbert and Lynch, which states that a distributed system can’t simultaneously guarantee all three of: Consistency, Availability, and Partition Tolerance.
In CAP terms:
consistency means every read sees the latest write (a single up-to-date copy of the data),
availability means the system remains operational and responsive (every request gets a non-error response), and
partition tolerance means it continues working despite network splits between nodes
The catch, according to CAP, is when you have a network partition or communication failure: you must choose between consistency and availability. You can’t have both in that moment.
In practical terms, CAP explains why different databases and systems make different trade-offs. For example, some traditional relational databases chose CA (Consistency + Availability, sacrificing partition tolerance). They would rather stop accepting writes than risk inconsistency, which is why a network glitch can make a primary-secondary database cluster read-only or offline – it’s preferring consistency over availability.
On the other hand, systems like Apache Cassandra or Amazon’s Dynamo go for AP (Availability + Partition tolerance), accepting that during a partition, nodes might return stale data rather than refuse service. A classic case is Dynamo powering Amazon’s shopping cart. Amazon deliberately favored availability: they decided it was better for the cart service to always accept writes (so customers can add items to their cart) even if some replicas are down, rather than reject adds during a failure. The consequence was that in rare cases, a customer might see an item reappear in their cart that they had removed, due to replicas reconciling after the fact. But Amazon deemed this an acceptable business trade-off – a slight inconsistency that a customer could easily fix was far better than losing sales because the cart was unavailable
It’s important to understand that partition tolerance is not optional in modern distributed systems
Partitions (network communication breaks) will happen, especially as systems grow geographically. So practically, you’re always choosing between C or A when a failure occurs. This doesn’t mean a system can’t be both consistent and available during normal operation.
One big lesson from the past decade is that consistency is a spectrum, and the CAP theorem’s classic form (“either consistent or available during a split”) is a bit oversimplified.
We have many shades of consistency in between. Terms like strong consistency (e.g. linearizability, which is what CAP “C” really refers to), eventual consistency, read-your-writes, monotonic reads, etc., describe various models of how up-to-date data is and what anomalies are allowed. For instance, eventual consistency (favored by AP systems) guarantees that if no new updates are made, eventually all replicas converge to the same state. But in the short term, you might read slightly stale data.
With experience, I learned to choose the right consistency model for the job. If I’m designing:
a banking system or a ledger, I likely need strong consistency
you don’t want two transactions seeing different balances.
a social media feed or a metrics collection pipeline, eventual consistency is usually fine
it’s more important that the system is always up than perfectly in sync at every millisecond.
Many large-scale architectures actually combine approaches: for critical data use a CP (consistent, partition-tolerant) system, for less critical features use an AP system.
Also, we started considering the nuance captured by the PACELC theorem: it extends CAP by saying
if a partition happens (P), choose A or C;
else (E, no partition) there’s still a trade-off between Latency (L) and Consistency (C).
In other words, even when the system is healthy, you often balance consistency versus performance. For example, a strongly consistent database might have higher latency for writes (since it synchronously replicates or locks), whereas an eventually consistent one can acknowledge writes faster at the cost of background synchronization.
Time, Clocks, and Ordering of Events
One of the trickiest mental models in distributed systems is time. On a single machine, you can often rely on a single clock or sequence of events to reason “what happened before what.” In a distributed system, there is no single global clock that all nodes agree on.
Clocks on different machines can drift or get out of sync, and message delays mean you cannot assume that “timestamp order” equals “actual order of events.” I learned this the hard way when debugging a log discrepancy: one server’s clock was 2 minutes behind, so its log timestamps made it look like events happened later than they actually did relative to the other components.
Leslie Lamport tackled this problem in his seminal paper “Time, Clocks, and the Ordering of Events in a Distributed System”. The solution he introduced is the idea of logical clocks – a way to order events without relying on perfectly synchronized physical clocks.
A Lamport clock is a simple counter each process increments and piggybacks on messages; by comparing these counters, you can establish an order of events (“happened-before” relationships) across the system
Lamport clocks give a partial order – they ensure if one event causally influences another, you’ll see that in the timestamps, but they can’t distinguish concurrent events perfectly. Later, vector clocks extended this concept by keeping an array of counters (one per process) to fully capture causal relationships.
With vector clocks, if two events are concurrent (neither caused the other), you’ll see it because their vectors will be incomparable (neither less-than nor greater-than). Systems like Dynamo use vector clocks on updates – e.g. when two clients update the same item independently, the database can detect a conflict because the vector clocks of those updates are concurrent. Then it knows to trigger a reconciliation (like merge the changes or ask the application to resolve the conflict).
the mental model here is: replace time with order.
That said, sometimes you really do need a global notion of time – for example, if you want to assign globally unique timestamps or do external consistency (where transactions across different sites respect a real-time order). Achieving this is very challenging. An impressive real-world solution is Google’s TrueTime system used in Spanner (a globally distributed database). TrueTime uses a combination of GPS and atomic clocks in data centers to keep time accurate within a known bound of error. Instead of assuming an exact same time everywhere, Spanner’s TrueTime API provides a time interval [earliest, latest] that is guaranteed to contain the absolute current time. By waiting out the uncertainty interval, Spanner ensures no two transactions overlap in a way that violates consistency. This is a huge engineering feat – essentially, Google solved the clock synchronization to a few milliseconds so that they can use timestamps for ordering without ambiguity. The fact that Spanner resorts to such measures underscores how hard time sync is. For most of us, it’s easier to design our systems to avoid relying on perfectly synchronized clocks.
Practically, in my designs, I avoid using system timestamps for critical ordering decisions. Instead, I’ll use techniques like Lamport timestamps or version numbers for ordering events, or I’ll designate a single leader to timestamp events if a total order is needed. And I always run NTP (Network Time Protocol) services to keep server clocks in sync as closely as possible – it’s not perfect, but every little bit helps. Also, when reading logs or debugging, I’m mindful that clocks can lie – so I look at logical sequence numbers or other corroborating evidence instead of assuming timestamp X on machine A is truly after timestamp Y on machine B.
To quickly recap, start with the basics: understand that networks are unreliable and slow compared to in-memory, so plan accordingly (timeouts, retries, async processing). Scale-out thoughtfully: splitting work across machines introduces overhead, so ensure the gain outweighs the cost. For data consistency, remember CAP – decide what’s more important for your scenario in a failure, and know that consistency isn’t just “strong or eventual” but a spectrum of models. Embrace logical clocks to reason about ordering, since wall clocks will deceive you. And when replicating, choose between strong consistency (with consensus algorithms ensuring a single truth at a performance cost) versus eventual consistency (allowing more flexibility and availability, but requiring conflict resolution). Modern cloud architectures often blend these approaches – for instance, a strongly consistent core (like a metadata store) with eventually consistent edges (like cache or analytics data) to balance correctness and performance.
Perhaps the most practical advice I can give is this: observe and learn from real-world outages and post-mortems. Every major distributed outage (whether it’s a cloud provider incident or a high-profile service going down) teaches us something about these principles. They usually boil down to a forgotten assumption – maybe someone assumed the network wouldn’t partition, or that a retry storm wouldn’t happen, or that a clock couldn’t jump backwards. By studying those, you reinforce these mental models in a visceral way. I still periodically revisit the classics (like Google’s “Lessons from distributed systems engineering” or James Hamilton’s blog) to see how theory meets practice.
Finally, if you’re venturing into building distributed systems: draw diagrams, devise mindmaps, and document your assumptions. It helps to visualize components and failure modes. I often sketch out what happens if service X is slow, or if database partition occurs – then see if our design still holds up.
Upcoming detailed articles on:
Replication
Consensus
Paxos
Raft
Sources:
Distributed systems for fun and profit, https://book.mixu.net/distsys/single-page.html
MapReduce, https://dl.acm.org/doi/pdf/10.1145/1327452.1327492
Time, Clocks, and the Ordering of Events in a Distributed System, https://dl.acm.org/doi/pdf/10.1145/359545.359563
Unpacking the eight fallacies of distributed computing, https://sookocheff.com/post/distributed-systems/unpacking-the-eight-fallacies-of-distributed-computing
The Raft Consensus Algorithm, https://raft.github.io