
Understanding Backpropagation
A Clear Guide from an ML Engineer

Let me explain backpropagation in the clearest way I know how. After years of building neural networks, I've found that the best explanations are the simple ones. So let's break down this fundamental algorithm that makes all of modern AI possible.
What Is Backpropagation, Really?
Backpropagation is how neural networks learn. It's the algorithm that figures out how to adjust every weight and bias in your network to reduce error. Think of it as the network's way of learning from its mistakes.
Here's the simplest way I can put it:
backpropagation calculates how much each weight contributed to the error, then adjusts all weights accordingly.
It does this by working backward from the output to the input—hence "back" propagation.
The Pizza Delivery App

Let me share my favorite analogy. Imagine you're running a pizza delivery company with multiple stages:
Order takers (input layer)
Kitchen staff (hidden layers)
Delivery drivers (output layer)
A customer complains their pizza arrived cold and late (this is your error). How do you figure out what went wrong?
You work backward:
First, ask the delivery driver: "How late were you?" (output layer error)
Then ask the kitchen: "Did you delay the order?" (propagate error backward)
Finally, check with order takers: "Did you write down the order correctly?" (input layer)
Each person's mistake affected the next person in line. The delivery driver might have been slow, but if the kitchen was 30 minutes late, that's the bigger issue.
Backpropagation figures out these "blame assignments" mathematically.
How Neural Networks Make Predictions (Forward Pass)
Before we can understand backpropagation, we need to understand the forward pass—how networks make predictions.
Imagine predicting if someone will like a movie based on just two factors:
How much action it has (0-10)
How much comedy it has (0-10)
# Super simple forward pass
action = 8
comedy = 3
# These are our weights (what the network learns)
weight_action = 0.7
weight_comedy = 0.3
bias = -2
# Calculate prediction
prediction = (action * weight_action) + (comedy * weight_comedy) + bias
# prediction = (8 * 0.7) + (3 * 0.3) + (-2) = 4.5
# Apply activation (sigmoid squashes between 0 and 1)
final_output = sigmoid(4.5)
# ≈ 0.989 (98.9% chance they'll like it)The network predicted 98.9% chance of liking the movie.
But what if the person actually hated it? That's where backpropagation comes in.
Working Backward..
To fix our prediction, we need to know how to adjust our weights.
Backpropagation answers three questions:
How wrong were we? (Calculate the error)
Who's to blame? (Distribute the error)
How do we fix it? (Adjust the weights)
Step 1: Calculate the Error
actual_rating = 0 # They hated it
predicted = 0.989 # We thought they'd love it
error = predicted - actual_rating # 0.989 (we were very wrong!)Step 2: The Chain Rule (The Heart of Backprop)
This is where people get confused, but it's actually simple. The chain rule says: to understand how A affects C through B, multiply how A affects B by how B affects C.
Let me make this concrete:
Changing the
weight_actionchanges thepredictionChanging the
predictionchanges thefinal_outputChanging the
final_outputchanges theerror
So to know how weight_action affects error, we multiply these relationships together:
# How much does weight_action affect the error?
gradient = error * sigmoid_derivative(prediction) * action
# = 0.989 * 0.0109 * 8
# = 0.086This gradient (0.086) tells us: "increasing weight_action by 1 would increase error by 0.086."
Step 3: Adjust the Weights
Since we want to reduce error, we move weights in the opposite direction of the gradient:
learning_rate = 0.1 # How big our steps are
weight_action = weight_action - (learning_rate * gradient)
# = 0.7 - (0.1 * 0.086)
# = 0.691We do this for every weight in the network, and that's backpropagation!
Why "Backward" Propagation?
The algorithm is called backpropagation because we calculate gradients by moving backward through the network:
Start at the output: Calculate how wrong we were
Move to previous layer: Calculate how much this layer contributed to the error
Keep going backward: Repeat until we reach the input
Update everything: Adjust all weights based on their contributions
It's like a detective story where you start with the crime (error) and work backward to find all the accomplices (weights that contributed).
Backpropagation automatically figures out what each layer should learn. You don't program these features—the network discovers them by minimizing error.
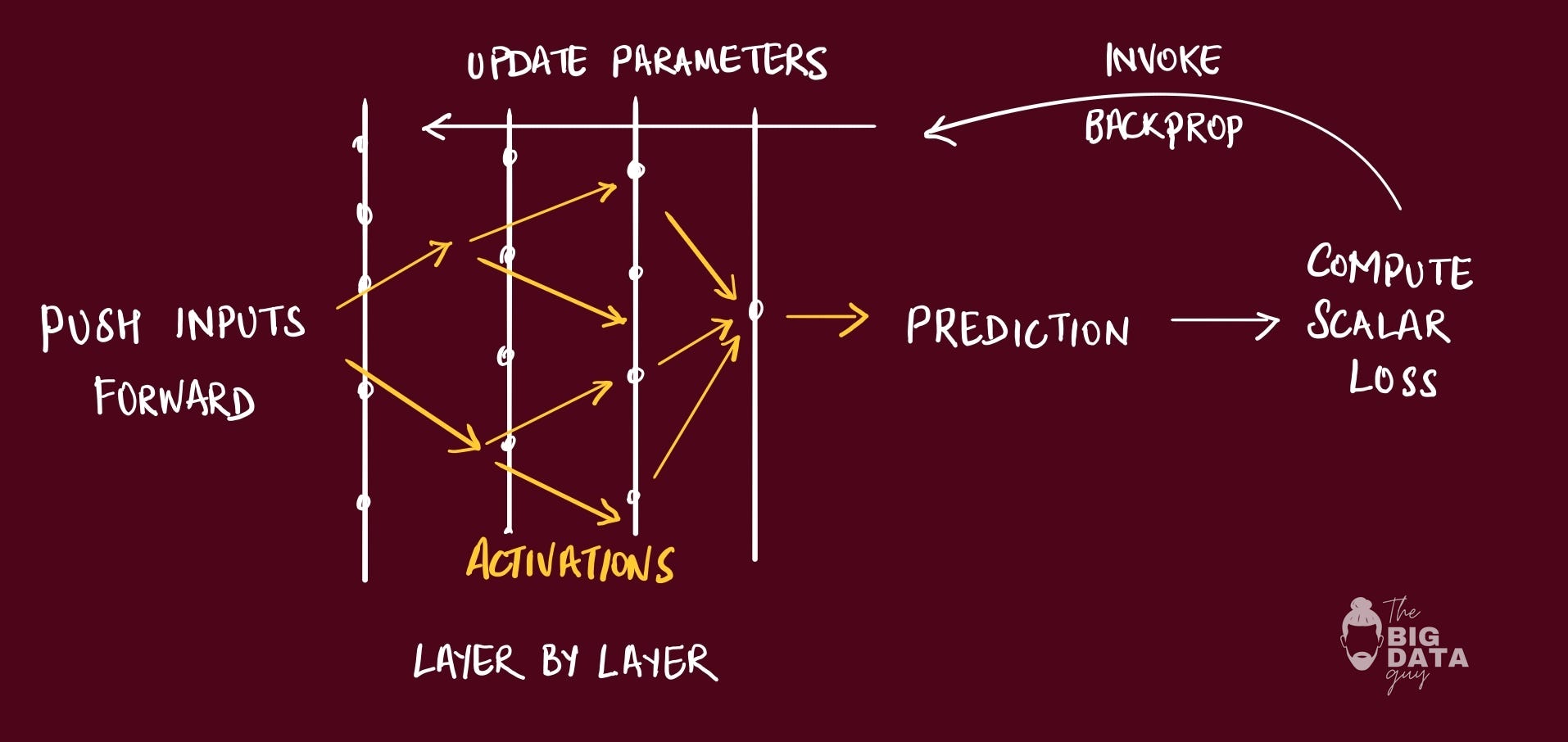
emphasizes proportionality..
For intuition, it starts at the outputs: nudge the correct logit up and the others down. Then “jump backward” one layer at a time, adjusting upstream weights that contributed to the mistake. You repeat this until you reach the inputs (which you don’t change).
Not every weight moves equally. Updates are scaled based on how much changing a particular weight will reduce the overall loss, some connections matter more for this example and get bigger adjustments.
Common Misconceptions I See
"Backprop is just for neural networks"
Actually, it's just an efficient way to calculate gradients. Any differentiable computation graph can use backprop.
"It updates weights randomly"
No! Every weight update is precisely calculated based on that weight's contribution to the error.
"Deeper networks always backpropagate better"
Not quite. Very deep networks can suffer from vanishing gradients—by the time the error signal travels back many layers, it becomes too small to be useful.
The Four Operations That Make It Work
At its core, backpropagation repeats four operations:
Multiply (apply weights)
Add (combine inputs and biases)
Activate (apply non-linearity like ReLU or sigmoid)
Differentiate (calculate gradients during backward pass)
Every complex neural network, from CNNs to Transformers, is just these operations arranged in different patterns.
Excellent! If you have reached this point, Good Job. Now we can go deeper..
How a Neural Network Learns
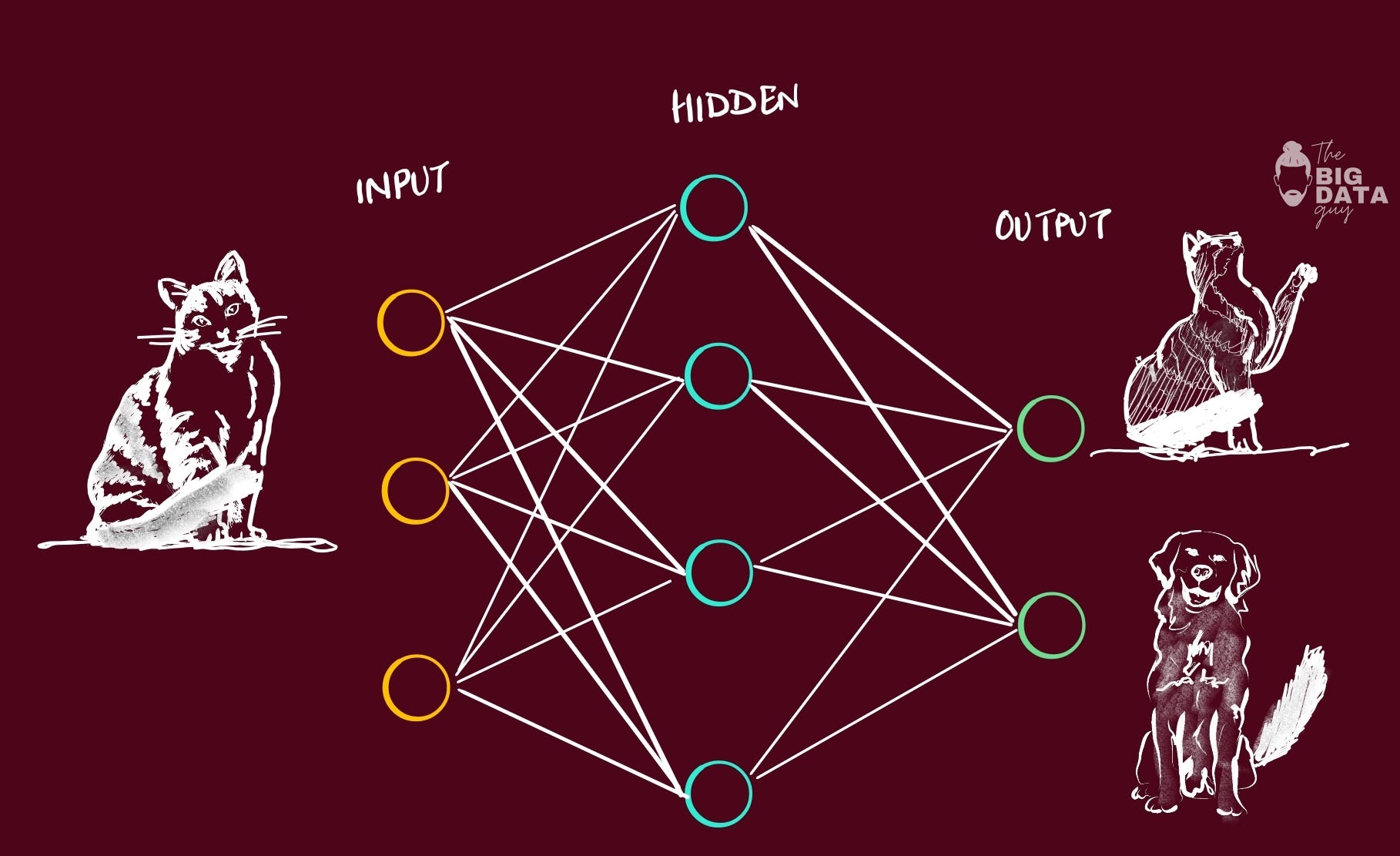
One single path of the data through the model = Epoch.
Same data is passed over and over again through multiple epochs, and it’s during this repeated process is when model would be learning.
When the model is first initialized, it’s set with arbitrary weights, for example:
At the end → model spit out the output for a given input. Then it would calculate the loss/error of that output by comparing prediction vs true label.
Using that we calculate the gradient of the loss function, w.r.t. each of the weights that have been set.
Gradient is just a derivative of a function with several variables
This gradient is then multiplied with the Learning Rate.
Learning Rate = very small number, usually between 0.1 to 0.001
That means the value of gradient is going to become relatively small once we multiply it with learning rate.
Then we update the specific weight with this new value calculated.
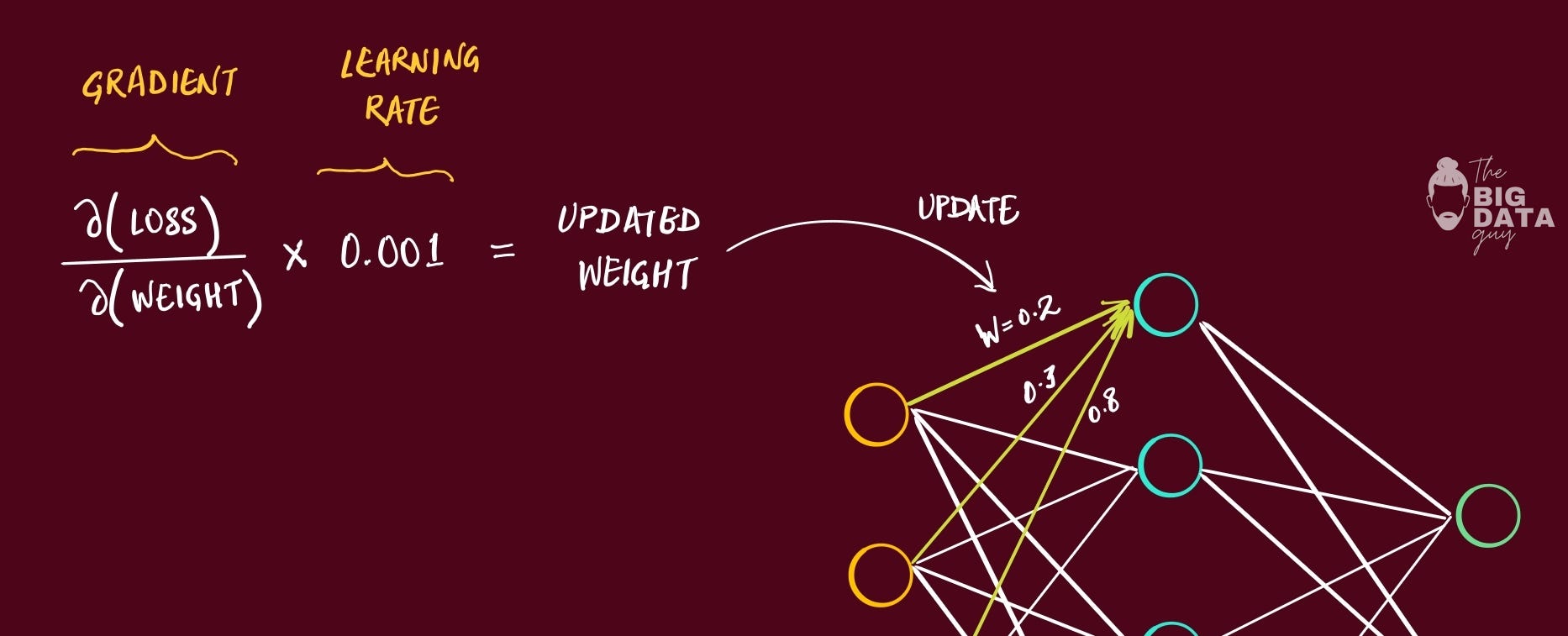
This process happens with each of the weights in the model, each time data passes through it. That means, for each epoch → we calculate gradient per weight → update that weight with the result.
Now imagine, with each epoch, all the weights in the model are going to be continously updated. They are going to incrementally get closer to the optimized values.
This updation of the weights is essentially what we mean when we say the model is learning.
The model is learning what values to assign to each weight based on those incremental changes.
How does this lead to backprop?
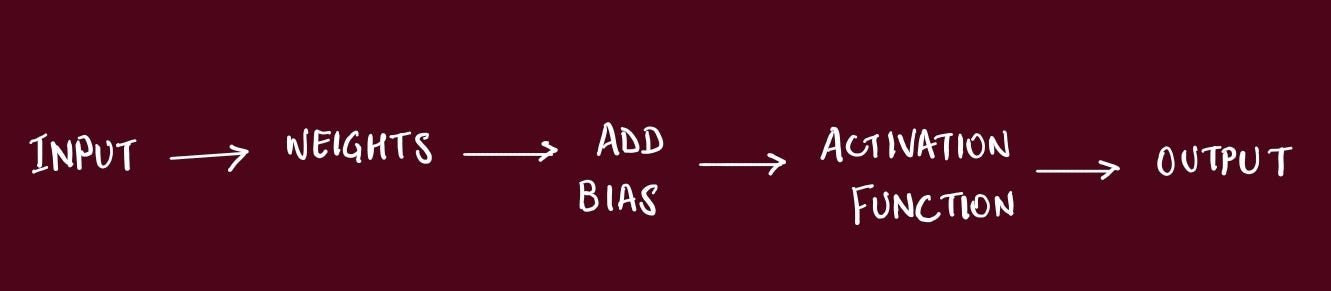
Push inputs forward layer-by-layer (weighted sums → activations) to get predictions → compute a scalar loss → then invoke backprop to obtain gradients so we can update parameters.The Four Equations That Run the World
Over the years, I've implemented backprop from scratch more times than I can count—in NumPy, C++, CUDA, even once in JavaScript for a browser demo. It always comes down to four fundamental equations that I call the "BP quartet".
BP1: Output Layer Error
“How wrong were we at the end?” times “how sensitive is the output gate right there?”
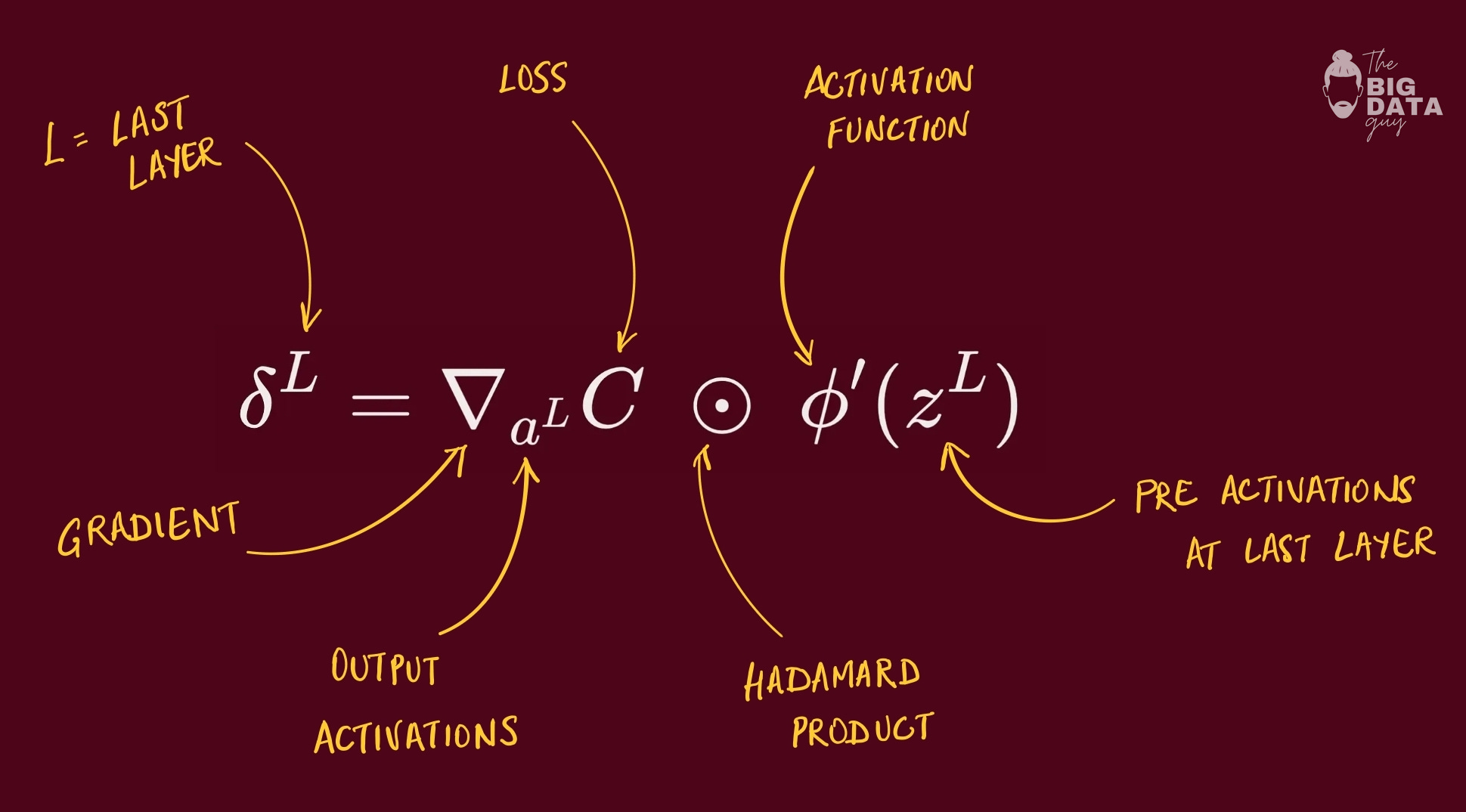
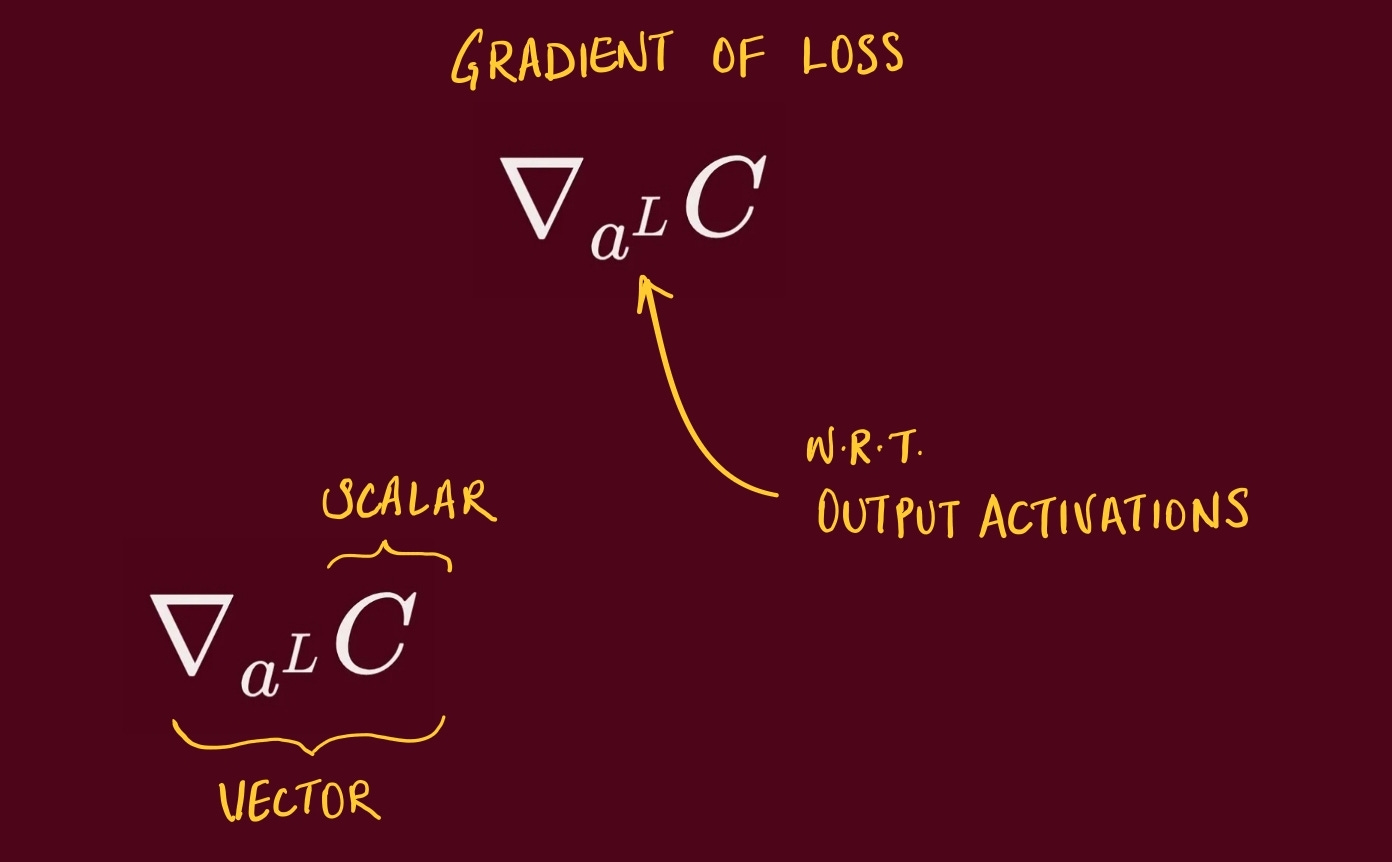
So simply put, first part of the equation is gradient of the loss w.r.t. the output activations (a vector).
Compute the gradient of the loss with respect to the output activations, then multiply element-wise by the derivative of the output activation evaluated at the pre-activations.
With common pairs like softmax + cross-entropy (or sigmoid + BCE), this simplifies to prediction minus target.
The result is the error signal for the output layer, same shape as the outputs.
BP2: Error Propagation
Pull the blame from the next layer back to the current layer, then scale by the weights.
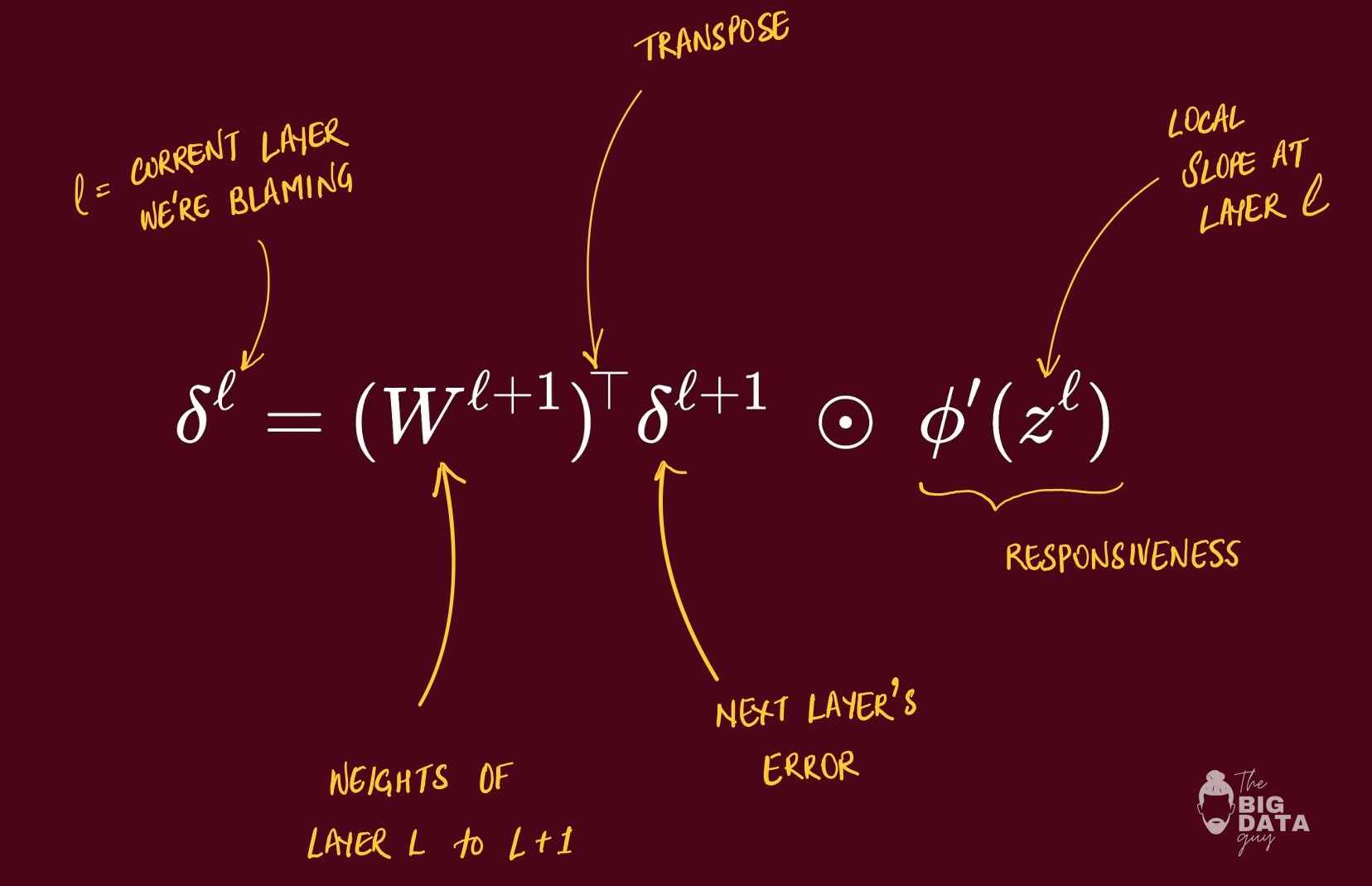
The next layer says, “these incoming weights caused trouble”. We route that blame backward along the same lines (transpose of W)
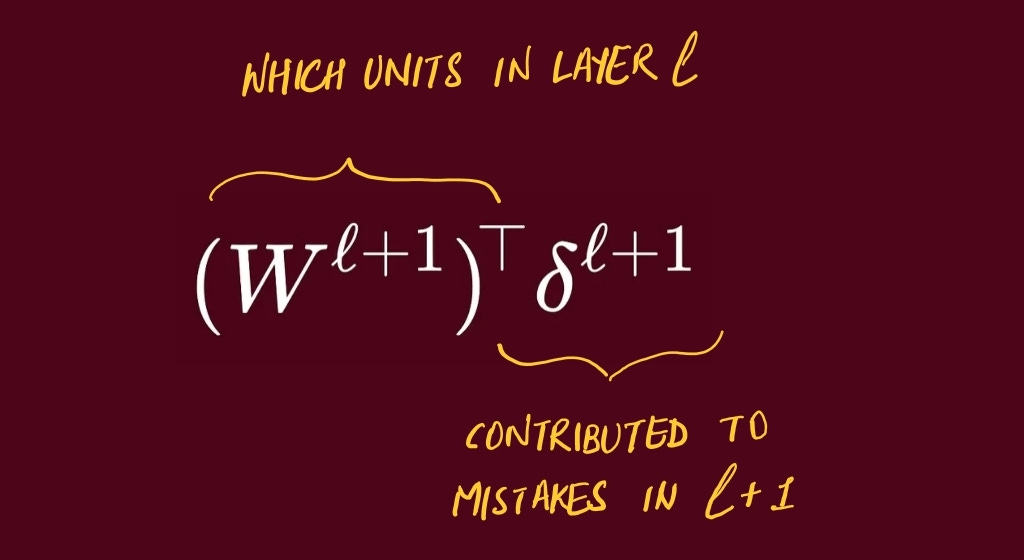
For a hidden layer, take the next layer’s error signal and multiply by the transpose of the connecting weight matrix to route blame backward.
Then multiply element-wise by the derivative of the current layer’s activation at its pre-activations.
This yields the error signal for the current layer, ready to pass further back.
BP3: Bias Gradient
The base setting’s gradient is just the blame at this layer. Nudging the layer’s baseline up shifts everything equally, so the “how much would the loss change?” is exactly the local blame.
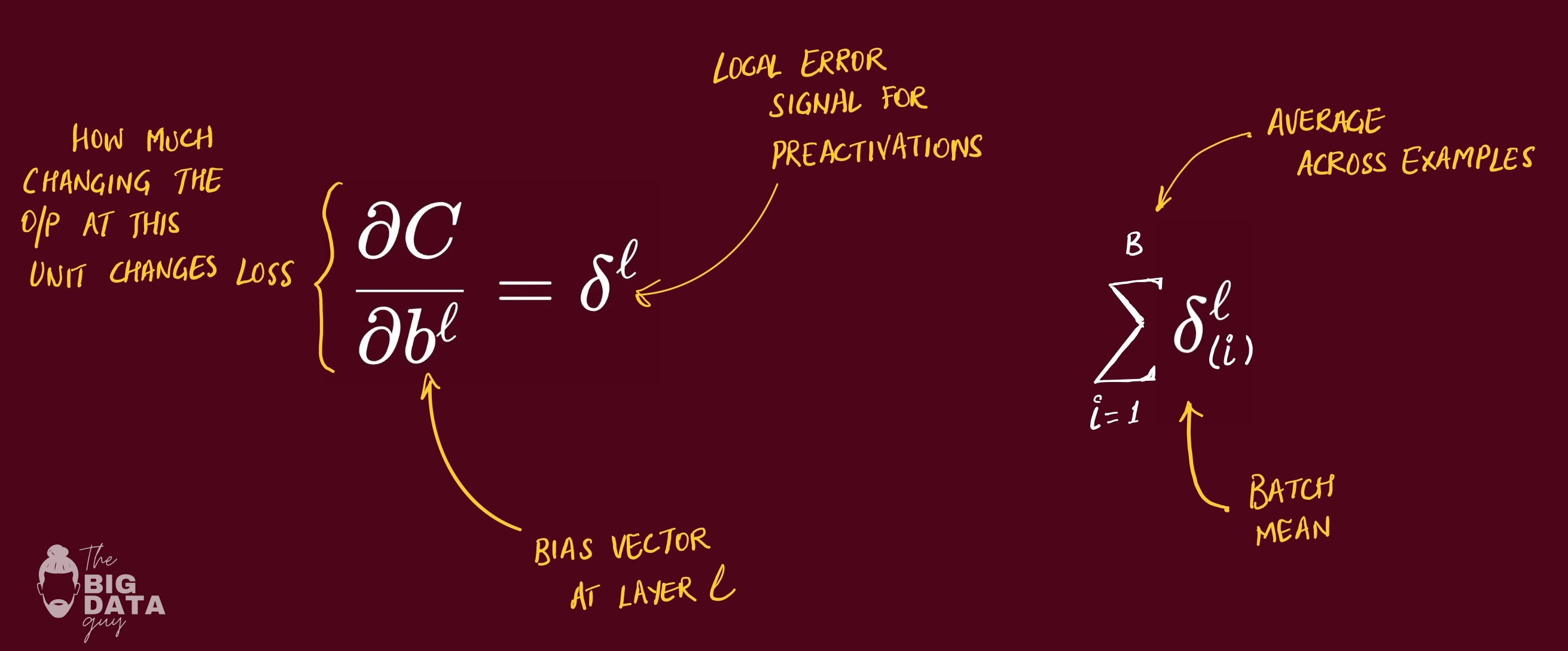
The gradient of the loss with respect to a layer’s bias vector equals that layer’s error signal. For mini-batches, reduce across the batch dimension (sum or mean) to get one bias gradient per unit.
No mixing terms appear because each bias influences only its own pre-activation.
BP4: Weight Gradient
Connection update = “blame at the destination” × “signal at the source.”
The gradient of the loss with respect to a layer’s weight matrix is the outer product of that layer’s error signal and the previous layer’s activations.
For mini-batches, sum or mean the outer products over examples.
The result has the same shape as the weight matrix and is used by the optimizer to update parameters.
TL;DR mental model
BP1: compute the final blame.
BP2: pass blame backward through the same pipes, gated by local slope.
BP3: bias update is just the local blame.
BP4: weight update is destination blame times source signal.
That’s it for now.. I am tired.