
The Profound Impact of Prompt Variations on Large Language Model Responses
The Prompt Precision Problem.

It's fascinating how insights from one field can illuminate another. I was recently reading a book on human psychology, and a particular passage stopped me in my tracks:
The way questions are worded is incredibly important. Changing just one word in a question can bring us a completely different range of solutions.
In an example to make airports more efficient, asking different questions, such as:
'How can we speed up the bags?'
'How can we slow down the passengers?'
'How can we reduce wait time?'
'How can we improve the wait experience?'
will lead to fundamentally different answers.
This idea, highlighting the subtle yet profound impact of framing on problem-solving.

Given this above is true for humans, do LLMs also have a similar behavior?
That means small changes to the prompt would generate different responses from LLMs?

Like humans, LLMs are profoundly sensitive to the way questions are asked. Minor variations in prompts can lead to dramatically different outcomes, impacting reliability, accuracy, and trust.
Prompt engineering serves as the essential interface between human users and the LLM system, acting as a critical determinant of output quality.
So, it’s natural to be of concern if LLMs show high responsiveness to subtle linguistic variations.
Recent research unequivocally confirms this phenomenon: LLMs are demonstrably sensitive to prompt variations. They are "notoriously sensitive to subtle variations in prompt phrasing and structure," with performance often diverging significantly across models and tasks based on these nuances.
This sensitivity extends beyond mere semantic content, encompassing the formatting, the order of information, and even the underlying sentiment embedded within prompts, all of which can lead to fundamentally different responses.
Even for tasks conventionally considered objective, the specific wording and structural composition of a prompt are critical determinants of the resultant output. This observed prompt sensitivity in LLMs bears a striking resemblance to well-documented phenomena in human cognition, where the framing or wording of a question can profoundly influence responses. For example, LLMs exhibit "response-order bias" and "label bias," demonstrating a preference for the first option presented or for certain labels, which is analogous to primacy effects or cognitive heuristics observed in human judgment. Similarly, the influence of prompt sentiment on factual accuracy and the propagation of biases in LLM outputs mirrors how human emotional states can affect information processing and decision-making. 1
This is fascinating, because the parallel between LLM prompt sensitivity and human cognitive biases suggests that LLMs, despite their artificial nature, have developed emergent processing patterns that are highly susceptible to linguistic framing. 2
This is not merely a mimicry of human behavior; it implies that the statistical patterns learned from vast human text data encode not just language itself, but also the biases inherent in human communication.
When presented with a prompt exhibiting these features, the model's generative process is steered towards outputs that reflect these learned correlations.
The Four Dimensions of Prompt Sensitivity
The arrangement and presentation of prompt elements significantly influence LLM performance.
Research shows that LLM performance is not just about words, but how they are presented. We’ll cover all 4 dimensions/levels of prompt sensitivity:
Prompt Formatting and Structural Impact
Order Sensitivity and Positional Biases
Sentiment-Induced Variations in LLM Outputs
Subtle Wording and Phrasing Nuances
Prompt Formatting and Structural Impact
Markdown/JSON/YAML vs plain text
code fences
delimiters
Beyond the explicit semantic content, the arrangement and presentation of prompt elements significantly influence LLM performance. Prompt formatting refers to the systematic arrangement and presentation of prompt content while preserving its semantic meaning. 3
Furthermore, it suggests a limitation in LLMs' ability to fully abstract away presentation details from the core meaning, indicating that their "understanding" is deeply rooted in the statistical properties of the input's surface form.
To address this complexity, methodologies like Content-Format Integrated Prompt Optimization (CFPO) have been introduced. CFPO jointly optimizes both prompt content and formatting through an iterative refinement process.

The Content-based Components define the information provided to the LLM, including:
Task Instruction defines the primary goal, guiding the model’s overall behavior.
Task Detail offers supplementary task-specific information, including resolution steps.
Output Format specifies the desired output structure (e.g., JSON, bullet points, etc.).
Few-shot Examples provide specific instances for contextual learning patterns.
Query shows the question or request to be answered by the LLM.
Order Sensitivity and Positional Biases
rearranging premises/options
changing few-shot example order
LLMs exhibit systematic biases based on the order in which information is presented within a prompt. This phenomenon includes "response-order bias," where LLMs demonstrate a tendency to favor the first option presented in a list or sequence. Additionally, "label bias" manifests as a preference for certain labels over others. For example, in one study, GPT-4 selected the first option in multiple-choice questions in over 63% of cases. 4
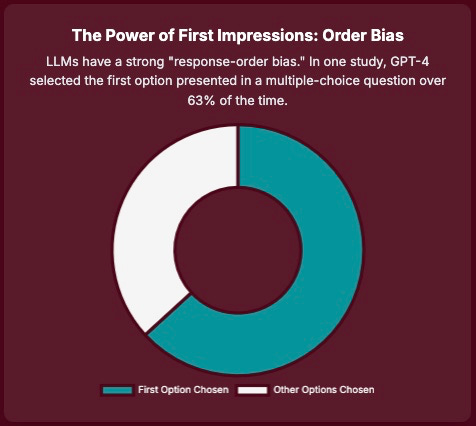
Even slight variations in input arrangement, such as shuffling options or content, consistently lead to inconsistent or biased outputs and measurable declines in output accuracy across diverse tasks, including paraphrasing, relevance judgment, and multiple-choice questions. Remarkably, even swapping two semantically identical choices can result in noticeable performance drops. 5
This inherent sequential processing means that the order of information is not merely a presentation detail but a core component of the input sequence that dictates how internal states are formed.

Response-Order Bias
Observed: GPT-4 picked the first option 63.21% of the time
Factors: Task complexity; input length; label type; framing
LLM/Task: GPT-4, Llama 3.1; MCQ; relevance judgment
Mitigation: Reduced but not eliminated (with justification)
Label Bias
Observed: GPT-4 chose “B” over “C” 74.27% of the time
Factors: Label type; framing
LLM/Task: GPT-4, Llama 3.1; MCQ
Mitigation: Reduced but not eliminated (with justification)
Performance Degradation (Shuffling)
Observed: Accuracy drops with shuffled inputs
Factors: Input length; task complexity
LLM/Task: GPT-4o, GPT-4o mini, DeepSeek; Paraphrasing, MSMARCO, MMLU
Mitigation: Mixed effectiveness (few-shot)
Sentiment-Induced Variations in LLM Outputs
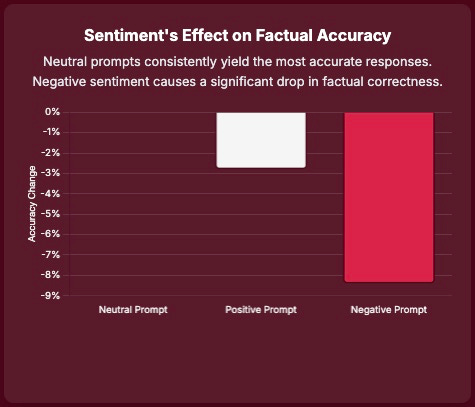
The sentiment conveyed in a prompt significantly influences LLM responses, affecting output quality, factual accuracy, and bias propagation. Prompts with negative sentiment are consistently associated with a substantial decrease in factual accuracy, approximately 8.4%, while positive prompts lead to a smaller reduction of about 2.8%. Conversely, neutral prompts consistently yield the most factually accurate responses across all tasks. 6
The finding that negative sentiment prompts reduce factual accuracy and amplify bias suggests a phenomenon akin to "emotional contagion" in LLMs, where the model's output quality is degraded by the affective tone of the input. This is a critical risk factor, as it implies that emotionally charged prompts, even if unintentional, can cause the generation of unreliable or harmful content, particularly in high-stakes domains.
LLMs are trained on vast amounts of human text, where emotional tone is often correlated with specific linguistic patterns, response lengths, and content types. For instance, negative or critical discussions might be shorter or more direct, while positive or affirming interactions might be more elaborate. The model learns these correlations.
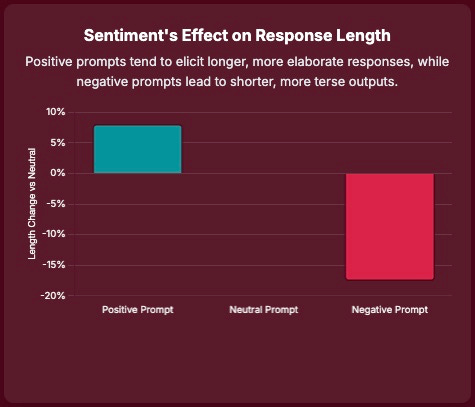
LLMs are more likely to amplify sentiment in subjective domains such as creative writing, journalism, and healthcare AI, where models may attempt to demonstrate empathy but inadvertently intensify negative emotional framing.
Subtle Wording and Phrasing Nuances
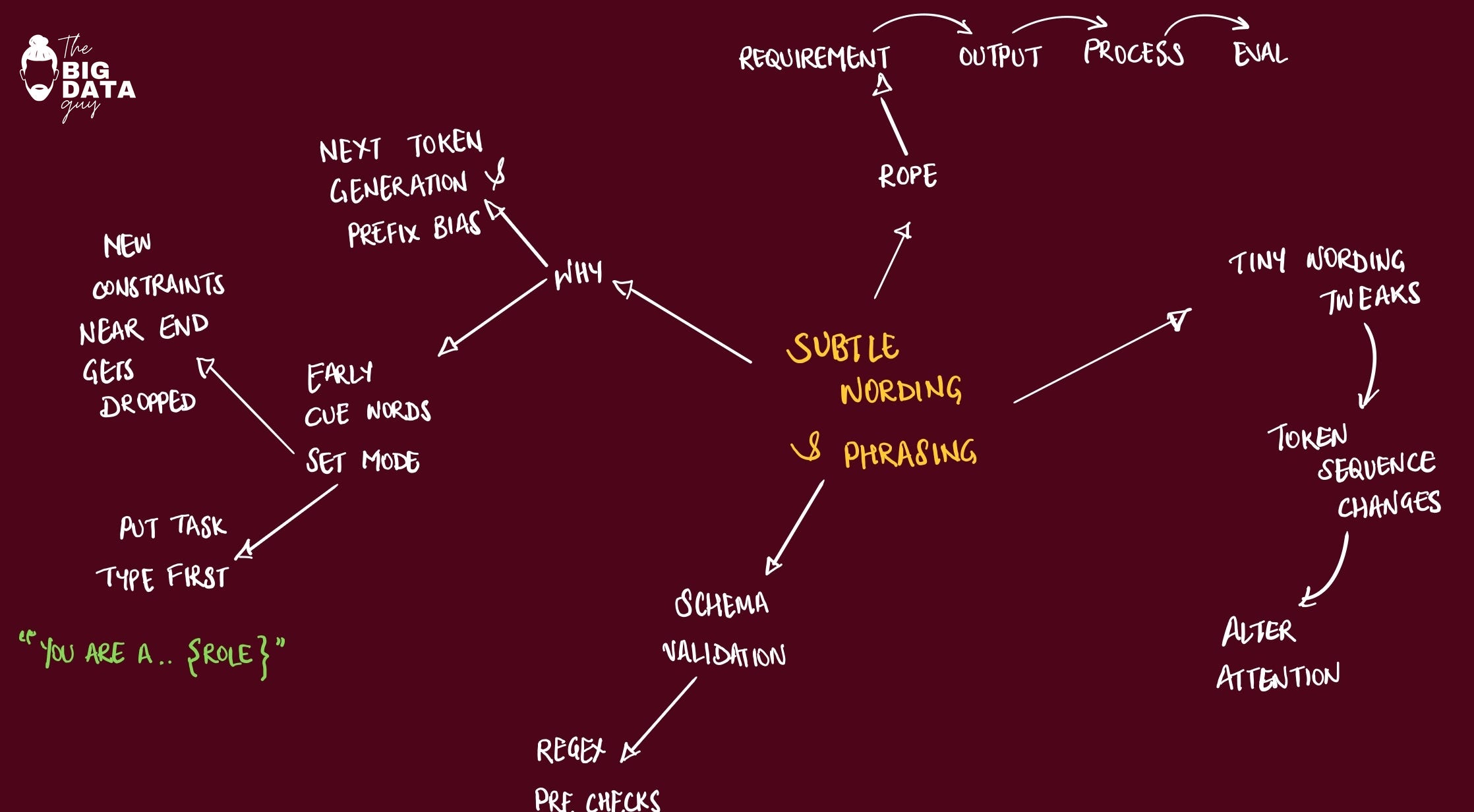
LLMs are not merely interpreting "meaning" but are processing the precise sequence of tokens and their statistical relationships as learned during training. LLMs, at their core, are complex statistical models that learn intricate patterns from massive datasets of text. Every word, punctuation mark, and grammatical construction is represented as a token, and the model learns the statistical likelihood of sequences of these tokens.
The model's "understanding" is an emergent property of these statistical relationships, not a deep conceptual grasp. Therefore, if a specific phrasing or the absence of a critical requirement (an omission) shifts this statistical landscape, it causes the model to follow a different generative path, leading to a different output.
The effectiveness of LLMs is fundamentally dependent on the design of effective prompts. Research on Requirement-Oriented Prompt Engineering (ROPE) demonstrates that focusing human attention on generating clear, complete requirements significantly enhances LLM performance.

Taming the Model: Mitigation and Best Practices
Strategies for Mitigating Prompt Sensitivity
A range of prompt engineering techniques has been developed to guide LLM behavior and enhance output quality, acknowledging their inherent sensitivity. These techniques aim to provide clearer instructions and richer context to the models:
Zero-shot Prompting: This is the most straightforward approach, instructing an LLM to perform a task without providing any examples within the prompt.
relies on the model's extensive pre-trained knowledge to understand and execute the task based solely on the instructions.
suitable for clear, concise tasks where pre-defined examples are not always available or necessary.
Few-shot Prompting: This technique involves including a small number of input-output examples directly within the prompt.
facilitates in-context learning, helping the model understand the desired task, output format, and style.
particularly useful for more complex tasks where zero-shot prompting may not yield satisfactory results.
Chain-of-Thought (CoT) Prompting: CoT prompting enhances the reasoning abilities of LLMs by instructing them to break down complex tasks into simpler, step-by-step sub-steps.
mimics human problem-solving approaches, enabling LLMs to tackle more intricate questions that require multi-step reasoning or calculations.
simple phrase like "Let's think step by step" can initiate zero-shot CoT, while providing explicit logical steps and examples can further guide the model.
Role Prompting: This creative and powerful technique involves assigning a specific persona or role to the LLM.
can dramatically alter the tone, style, and content of the model's responses, allowing for tailoring outputs to specific needs or scenarios.
Task Decomposition: This strategic approach breaks down complex tasks into smaller, more manageable subtasks.
leverages the LLM's ability to handle discrete pieces of information and
then combine them into a cohesive whole, making intricate problems more tractable.
Constrained Prompting: This technique involves imposing specific rules or limits on the LLM's output, such as word count limits, adherence to specific writing styles, or avoidance of certain topics.
especially valuable in professional settings where consistency and adherence to guidelines are crucial.
Iterative Refinement: This approach recognizes that complex tasks often require multiple rounds of revisions and improvements.
involves using multiple prompts to progressively improve and refine the LLM's outputs, allowing for continuous adjustment based on previous responses.
Contextual Prompting: This technique involves providing relevant background information or context to the LLM before asking it to perform a task. This helps the model understand the broader picture and generate more accurate and relevant responses by grounding its understanding in the provided context.
The Experiment
TL;DR (for SDEs & AI engineers)
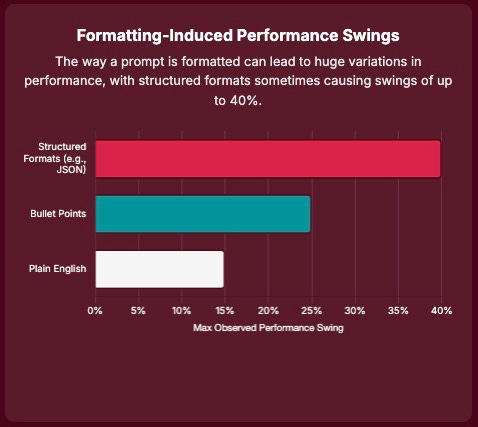
Yes, format matters — a lot. Swapping the format (plain text vs. Markdown vs. JSON vs. YAML) while keeping the content identical can swing scores by 2–3× on some tasks, and the effect is statistically significant across benchmarks.
Bigger models are steadier. GPT-4 variants are more robust and consistent than GPT-3.5 across formats; GPT-4-1106-preview shows the lowest dispersion.
No one-format-to-rule-them-all. Optimal formats don’t transfer cleanly across models; even within the GPT family, best templates differ (e.g., GPT-3.5 tends to like JSON; GPT-4 often favors Markdown). Validate per model & task.
Experimental Design
The tasks:
Natural language → natural language (NL2NL) 7
You talk to the model in everyday language, and it answers in everyday language.
Examples:“Which option is correct for this question?” (general knowledge / reasoning)
“Find all company names in this paragraph.” (entity tagging)
Natural language → code (NL2Code)
You describe what a function should do, and the model writes the code.
Examples:“Write a Python function that returns the nth Fibonacci number.”
“Here are a few input–output pairs—write the function that produces those outputs.”
Code → code (Code2Code)
You give the model code and ask it to translate or rewrite it.
Examples:“Convert this Java method to C#.”
“Rewrite this Python snippet into a more efficient version (same behavior).”
The formats:
What was tested? Keeping the prompt content constant (persona, task, examples, output instructions, user ask) and only changed the outer format: plaintext vs. Markdown vs. YAML vs. JSON.
Same content, four wrappers — plain text, Markdown, JSON, YAML. Only structure/syntax changed.
Plain text (good baseline)
“You are a helpful {role}. Task: {what to do}. Rules: 1) … 2) … Output: Return only {schema}.”Markdown (human-readable structure)
## Role, ## Task, ## Rules, ## Output, fenced code blocks for examples.JSON (machine-parseable)
{"persona":"…","instructions":["…","…"],"examples":[{"in":"…","out":"…"}],
"output_format":"Return JSON: {…}","input":"{USER_ASK}"}YAML (also human-friendly)
persona: …
instructions:
- …
examples:
- in: …
out: …
output_format: Return YAML with fields: …
input: "{USER_ASK}"
Prompts consistently included: persona, instructions, examples, output-format instructions, and the user ask.
Persona: Providing identity/context about the model's role in the task.
Task Instructions: Clear directives on what is expected from the model.
Examples: Five-shot examples to illustrate the expected inputs and outputs.
Output Format Instructions: Guidance on how to structure the responses.
User Ask: The variable context or question specific to that instance.
The models:
GPT-3.5:
gpt-35-turbo-0613,gpt-35-turbo-16k-0613GPT-4:
gpt-4-32k-0613,gpt-4-1106-preview(128k ctx)
What was found
1) Format changes can move scores by a lot
For GPT‑3.5-turbo, JSON or YAML sometimes helped a lot; for GPT‑4 variants, Markdown often did best on several tasks, but not always.
There is no single best format across all tasks and models.
For example, GPT‑3.5‑turbo leaned toward JSON wins; GPT‑4 more often favored Markdown on several benchmarks, but had exceptions
Bottom line: format is not cosmetic; it’s a performance knob.
2) Larger models are more stable across formats
Larger/newer models (GPT‑4‑1106‑preview) were generally more robust to format changes (tighter performance spread), but still not format-invariant.
3) No single template wins everywhere
The study stresses there’s no universally optimal format, even within the same model family. Validate per model & task.
Maintain a per-model, per-task “prompt format registry” with candidates: plaintext, Markdown, YAML, JSON.
4) A known failure mode to watch for
On HumanEval,
GPT-4-32k + JSON sometimes writes chain-of-thought text but stops before emitting code, tanking pass@1.
the “laziness” fix discussed by OpenAI 8
Immediate, practical advice
Pick a sensible default format per model
For GPT-4, use a clean Markdown frame (sections + fenced code blocks).
For GPT-3.5, prefer machine-parseable formats (JSON/YAML) when you need strict structure.
Match the wrapper to the job
Reasoning / Q&A / extraction: start with Plain text or Markdown (short rules, bullets).
Code generation: ask for the answer as the first fenced code block (Markdown). This avoids a failure mode observed with certain GPT-4 settings where the model “thinks” but doesn’t emit code.
Code translation: lean JSON for predictable diffs & toolchains
Avoid known sharp edges
For GPT-4, don’t ask for JSON-wrapped solutions; it sometimes stops before printing code.
Prefer bullet-list options over prose
Prompts with bullet points format typically enhanced performance metrics across most tasks when compared to prompts with plain descriptions formats.
The plain descriptions format, conversely, led to significant decreases in performance for many tasks, suggesting it could hinder the model's ability to accurately process and respond to prompts. 9
Ask first, then show the list.
Write the question (what to classify) above the list, then the options each on their own bullet.
Tell the model to output only one label
End the prompt with a single, strict instruction like:
“Return exactly one of..”
Prompt Sentiment: The Catalyst for LLM Change - arXiv, https://arxiv.org/html/2503.13510v1
A Human-AI Comparative Analysis of Prompt Sensitivity in LLM-Based Relevance Judgment - arXiv, https://arxiv.org/html/2504.12408v1
Beyond Prompt Content: Enhancing LLM Performance via Content-Format Integrated Prompt Optimizationt - arXiv, https://arxiv.org/html/2502.04295v3
Prompt architecture induces methodological artifacts in large language models, https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0319159
The Order Effect: Investigating Prompt Sensitivity to Input Order in LLMs - arXiv, https://arxiv.org/html/2502.04134v2
Prompt Sentiment: The Catalyst for LLM Change - arXiv, https://arxiv.org/html/2503.13510v1
Does Prompt Formatting Have Any Impact on LLM Performance? - arXiv, https://arxiv.org/html/2411.10541v1
How to deal with “lazy” GPT 4, https://community.openai.com/t/how-to-deal-with-lazy-gpt-4/689286
Effect of Selection Format on LLM Performance - arXiv, https://arxiv.org/html/2503.06926v2